17.5 Model evaluation and selection
How fair is each model?
How wrong is each model?
How accurate are each model posterior prediction?
For 2:
pp_check(complete_pooled_model) +
labs(x = "net", title = "complete pooled model")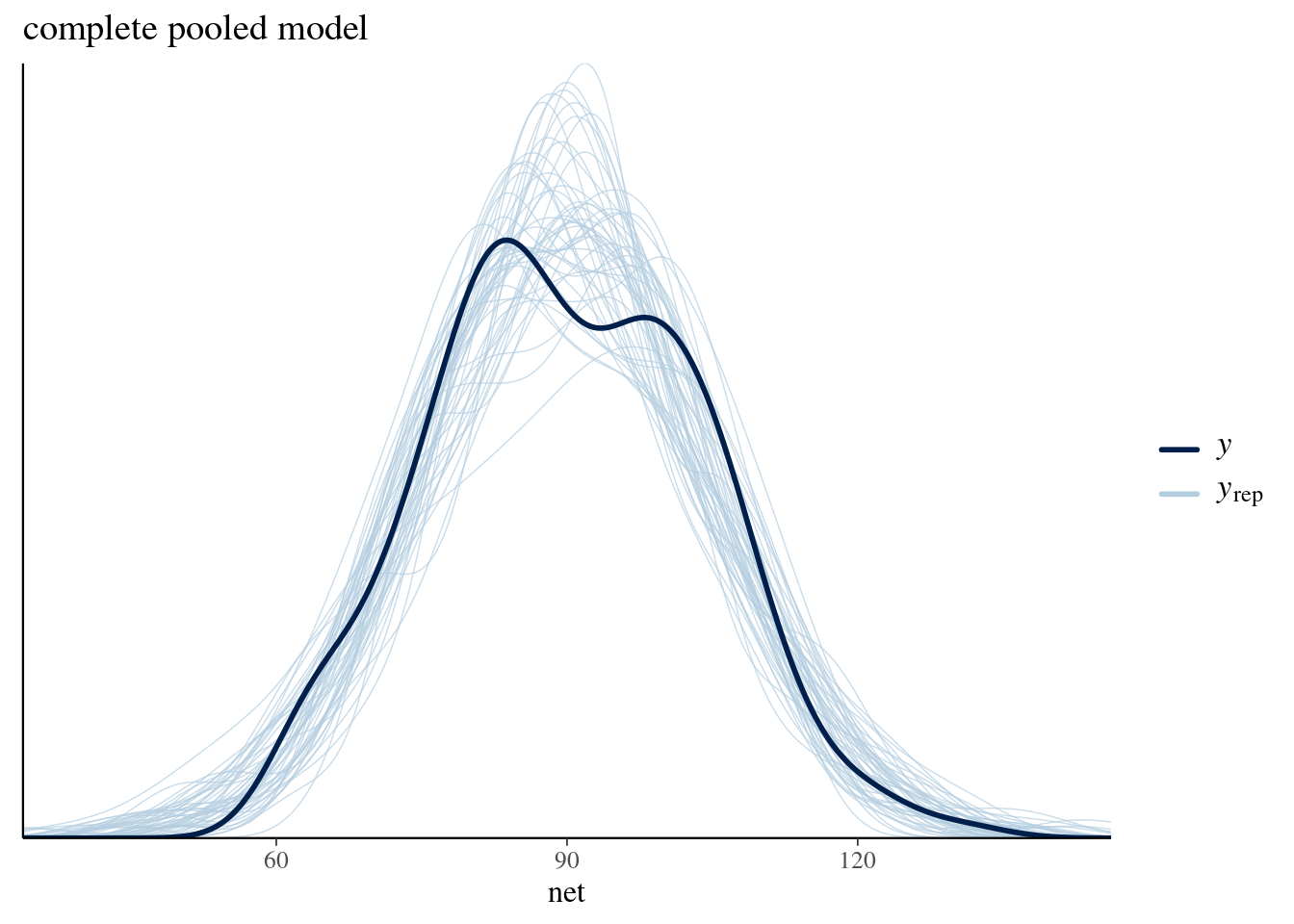
pp_check(running_model_1) +
labs(x = "net", title = "running model 1")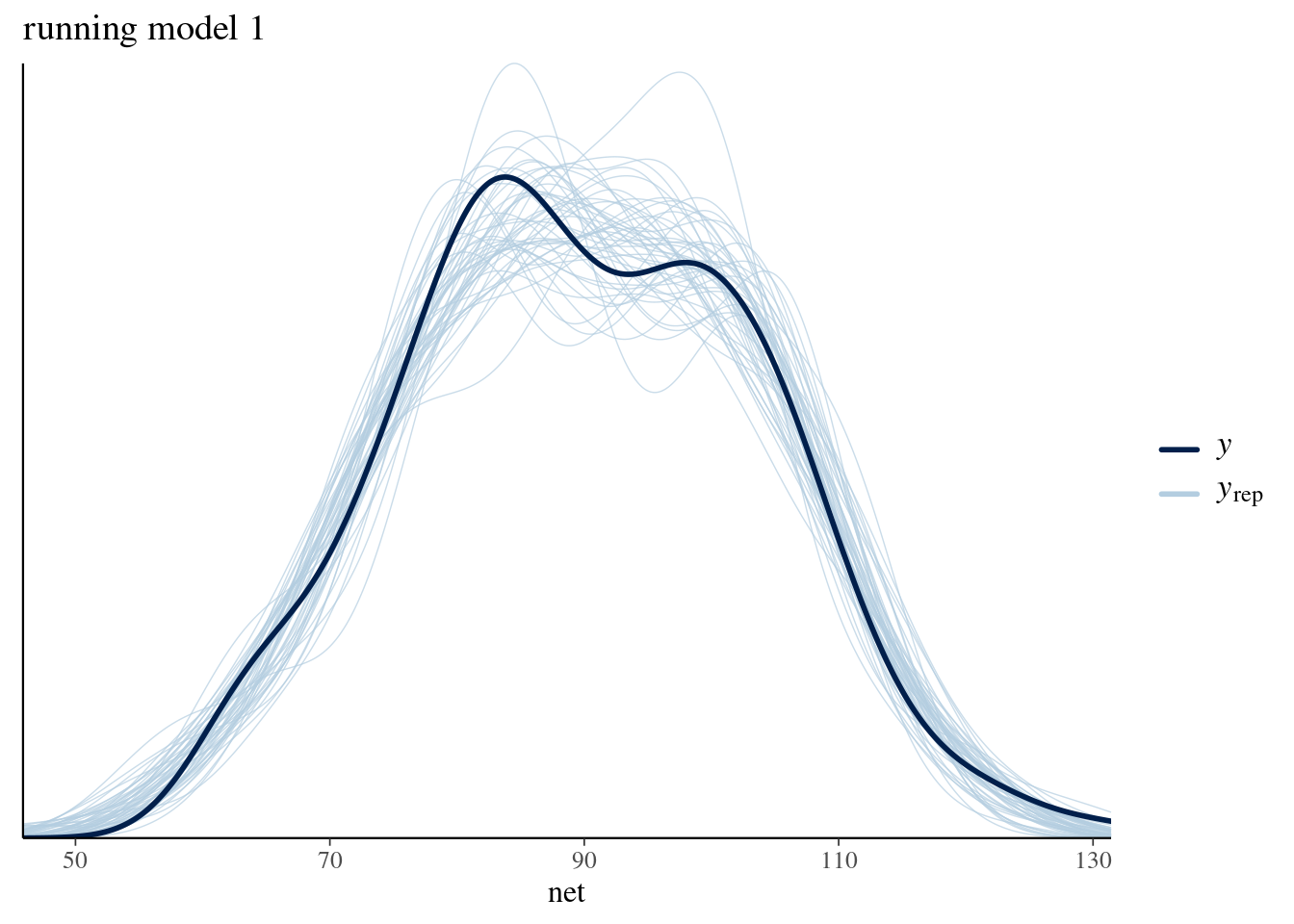
# Not displaying because MCMC of running_model_2 is to slow
# pp_check(running_model_2) +
# labs(x = "net", title = "running model 2")We can drop the complete pooled model.
# Calculate prediction summaries
set.seed(84735)
prediction_summary(model = running_model_1, data = running)
mae mae_scaled within_50 within_95
1 2.626 0.456 0.6865 0.973
prediction_summary(model = running_model_2, data = running)
mae mae_scaled within_50 within_95
1 2.53 0.4424 0.7027 0.973they are very close!
But what about “unknown data”?
We will use CV but here we divide runners.
(I did not run it as I was afraid of computation time!)
Using expected log-predictive densities (ELPD) we do not find significant difference in posterior accuracy for the two models.
Is the additional complexity worth it? Here no.