16.1 Data Set!
data(spotify, package = "bayesrules")We are going to use a subset Spotify data set from #TidyTuesday:
- 44 artists -> 350 songs
spotify <- spotify |>
select(artist, title, popularity) |>
mutate(artist = fct_reorder(artist, popularity, .fun = 'mean'))table(spotify$artist) |> hist(xlab = "Songs/artist", col = 4)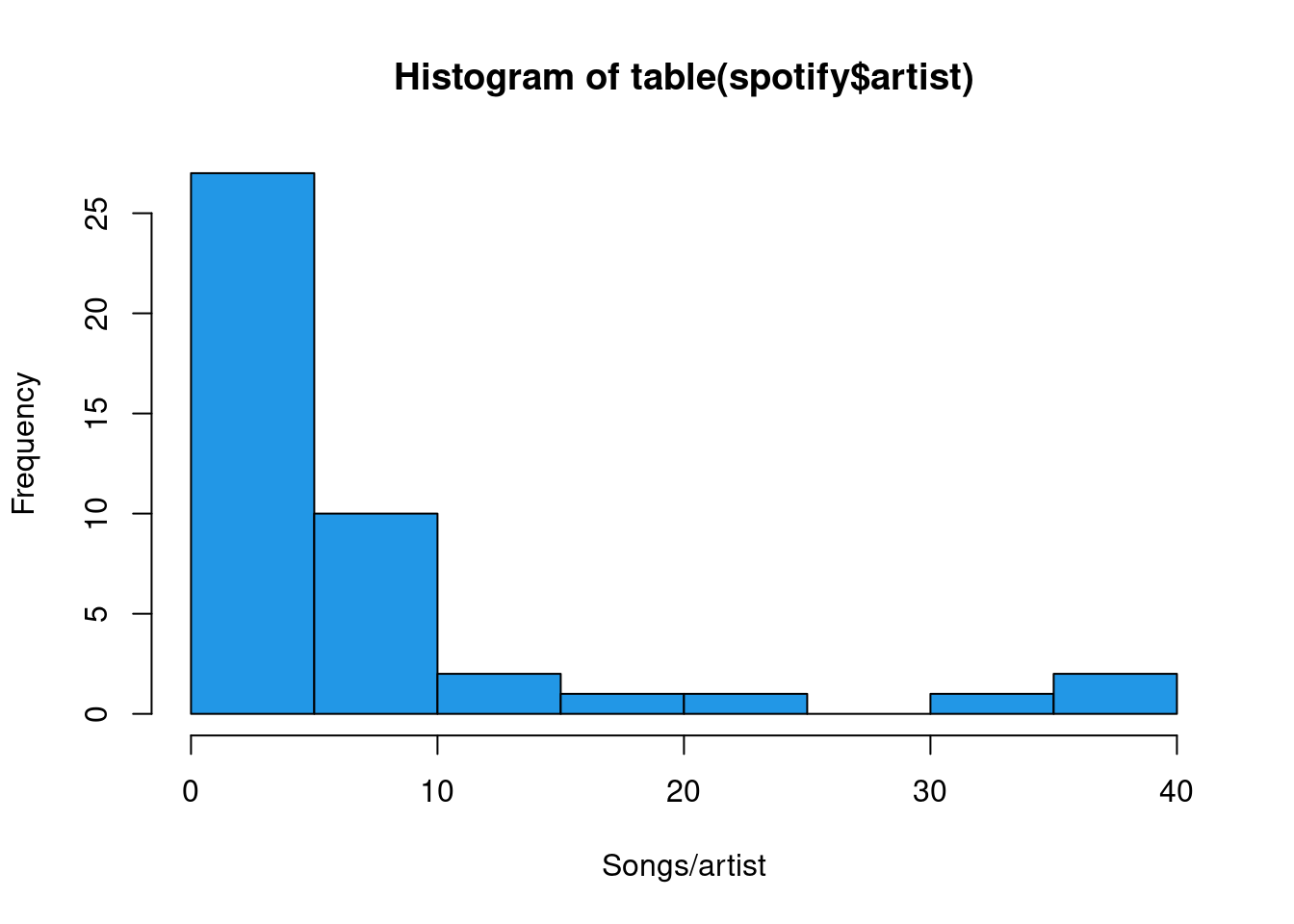
We are going to illustrate the 3 approaches seen in chapter 15:
- Complete pooling
- No pooling
- Partial pooling
Btw my top 3 most listening song/group from last week are:
- Dina Summer - Passion (cover)
- The Do - Anita No
- Purrrple cat - stream