Introduction to Statistical Learning Using R Book Club
Welcome
Book club meetings
1st edition vs 2nd edition
Pace
1
Introduction
1.1
What is statistical learning?
1.2
Why ISLR?
1.3
Premises of ISLR
1.4
Notation
1.5
What have we gotten ourselves into?
1.6
Where’s the data?
1.7
Some useful resources:
1.8
What is covered in the book?
1.9
How is the book divided?
1.10
Some examples of the problems addressed with statistical analysis
1.11
Datasets provided in the ISLR2 package
1.11.1
Example datasets
1.12
Meeting Videos
1.12.1
Cohort 1
1.12.2
Cohort 2
1.12.3
Cohort 3
1.12.4
Cohort 4
1.12.5
Cohort 5
2
Statistical Learning
2.1
What is Statistical Learning?
2.1.1
Why Estimate
\(f\)
?
2.1.2
How do we estimate
\(f\)
?
2.1.3
Prediction Accuracy vs Model Interpretability
2.1.4
Supervised Versus Unsupervised Learning
2.1.5
Regression Versus Classification Problems
2.2
Assessing Model Accuracy
2.2.1
Measuring Quality of Fit
2.2.2
The Bias-Variance Trade-Off
2.2.3
The Classification Setting
2.3
Exercises
2.4
Meeting Videos
2.4.1
Cohort 1
2.4.2
Cohort 2
2.4.3
Cohort 3
2.4.4
Cohort 4
2.4.5
Cohort 5
3
Linear Regression
3.1
Questions to Answer
3.2
Simple Linear Regression: Definition
3.3
Simple Linear Regression: Visualization
3.4
Simple Linear Regression: Math
3.4.1
Visualization of Fit
3.5
Assessing Accuracy of Coefficient Estimates
3.6
Assessing the Accuracy of the Model
3.7
Multiple Linear Regression
3.7.1
Important Questions
3.8
Qualitative Predictors
3.9
Extensions
3.10
Potential Problems
3.11
Answers to the Marketing Plan questions
3.12
Comparison of Linear Regression with K-Nearest Neighbors
3.13
Meeting Videos
3.13.1
Cohort 1
3.13.2
Cohort 2
3.13.3
Cohort 3
3.13.4
Cohort 4
3.13.5
Cohort 5
4
Classification
4.1
An Overview of Classification
4.2
Why NOT Linear Regression?
4.3
Logistic Regression
4.3.1
The Logistic Model
4.3.2
Estimating the Regression Coefficient
4.3.3
Multiple Logistic Regression
4.3.4
Multinomial Logistic Regression
4.4
Generative Models for Classification
4.5
A Comparison of Classification Methods
4.5.1
Linear Discriminant Analysis for p = 1
4.5.2
Linear Discriminant Analysis for p > 1
4.5.3
Quadratic Discriminant Analysis (QDA)
4.5.4
Naive Bayes
4.6
Summary of the classification methods
4.6.1
An Analytical Comparison
4.6.2
An Empirical Comparison
4.7
Generalized Linear Models
4.8
Linear regression with count data - negative values
4.9
Linear regression with count data - heteroscedasticity
4.10
Problems with linear regression of count data
4.11
Poisson distribution
4.12
Poisson Regression Model mean (lambda)
4.13
Estimating the Poisson Regression parameters
4.14
Interpreting Poisson Regression
4.15
Advantages of Poisson Regression
4.16
Generalized Linear Models
4.17
Addendum - Logistic Regression Assumptions
4.18
Lab: Classification Methods
4.19
Exercises
4.19.1
Conceptual
4.20
Meeting Videos
4.20.1
Cohort 1
4.20.2
Cohort 2
4.20.3
Cohort 3
4.20.4
Cohort 4
4.20.5
Cohort 5
5
Resampling Methods
5.1
Validation Set Approach
5.2
Validation Error Rate Varies Depending on Data Set
5.3
Leave-One-Out Cross-Validation (LOOCV)
5.4
Advantages of LOOCV over Validation Set Approach
5.5
k-fold Cross-Validation
5.6
Graphical Illustration of k-fold Approach
5.7
Advantages of k-fold Cross-Validation over LOOCV
5.8
Bias-Variance Tradeoff and k-fold Cross-Validation
5.9
Cross-Validation on Classification Problems
5.10
Logistic Polynomial Regression, Bayes Decision Boundaries, and k-fold Cross Validation
5.11
The Bootstrap
5.12
A simple bootstrap example
5.13
Population Distribution Compared to Bootstrap Distribution
5.14
Bootstrap Standard Error
5.15
Lab: Cross-Validation and the Bootstrap
5.15.1
The Validation Set Approach
5.15.2
Leave-One-Out Cross-Validation
5.15.3
k-Fold Cross-Validation
5.15.4
The Bootstrap
5.16
Meeting Videos
5.16.1
Cohort 1
5.16.2
Cohort 2
5.16.3
Cohort 3
5.16.4
Cohort 4
5.16.5
Cohort 5
6
Linear Model Selection and Regularization
6.1
Subset Selection
Best Subset Selection (BSS)
BSS Algorithm
Best Subset Selection (BSS)
Forward Stepwise Subset Selection (FsSS)
Backward Stepwise Subset Selection (BsSS)
Hybrid searches
Choosing the best model
Adjustment Methods
Avoiding Adjustment Methods
6.2
Shrinkage Methods
Overview
OLS review
Ridge Regression
Ridge Regression, Visually
Preprocessing
The Lasso
The Lasso, Visually
How lasso eliminiates predictors.
Bayesian Interpretation
6.3
Dimension Reduction Methods
The Math
Principal Components Regression
Partial Least Squares
6.4
Considerations in High Dimensions
Lasso (etc) vs Dimensionality
6.5
Exercises
6.5.1
Exercise 7
6.6
Meeting Videos
6.6.1
Cohort 1
6.6.2
Cohort 2
6.6.3
Cohort 3
6.6.4
Cohort 4
6.6.5
Cohort 5
7
Moving Beyond Linearity
7.1
Polynomial and Step Regression
7.2
Splines
7.3
Generalized Additive Models
7.4
Conceptual Exercises
7.5
Applied Exercises
7.6
Meeting Videos
7.6.1
Cohort 1
7.6.2
Cohort 2
7.6.3
Cohort 3
7.6.4
Cohort 4
7.6.5
Cohort 5
8
Tree-based methods
8.1
Introduction: Tree-based methods
8.2
Regression Trees
8.3
Terminology:
8.4
Interpretation of results: regression tree (Hitters data)
8.5
Tree-building process (regression)
8.6
Recursive binary splitting
8.7
Recursive binary splitting (continued)
8.8
But…
8.9
Pruning a tree
8.10
An example: tree pruning (Hitters data)
8.11
Classification trees
8.12
Classification trees (continued)
8.13
Example: classification tree (Heart data)
8.14
Advantages/Disadvantages of decision trees
8.15
Bagging
8.16
Bagging (continued)
8.17
Out-of-bag error estimation
8.18
Variable importance measures
8.19
Random forests
8.20
Random forests: advantages over bagging
8.21
Example: Random forests versus bagging (gene expression data)
8.22
Boosting
8.23
Boosting algorithm
8.24
Example: Boosting versus random forests
8.25
Bayesian additive regression trees (BART)
8.26
But first, BART notation:
8.27
Now, the BART algorithm
8.28
BART algorithm: iteration 2 and on
8.29
BART algorithm: figure
8.30
BART: additional details
8.31
To apply BART:
8.32
Lab: Tree-Based Methods - Fitting Classification Trees
8.33
Exploratory Data Analysis (EDA)
8.34
Correlation Analysis
8.35
Build a model
8.36
Visualize our decision tree
8.37
Evaluate the model
8.38
Tuning the model
8.39
Evaluate the model
8.40
Visualize the tuned decision tree (classification)
8.41
Variable importance
8.42
Final evaluation
8.43
Fitting Regression Trees
8.44
Decision Trees (Regression) Explained (StatQuest)
8.44.1
EDA
8.45
Correlation Analysis
8.46
Build a regression tree
8.47
Visualize our decision tree
8.48
Evaluate the model
8.49
Tuning the regression model
8.50
Evaluate the model
8.51
Visualize the tuned decision tree (regression)
8.52
Variable importance
8.53
Final evaluation
8.54
Bagging and Random Forests
8.55
Random Forest Diagram
8.56
Example
8.57
Evaluate the model
8.58
Variable importance
8.59
Random Forest using a set of features (mtry)
8.60
Evaluate the model
8.61
Variable importance
8.62
Boosting
8.63
Evaluate the model
8.64
Tuning the xgboost regression model
8.65
Grid tuning with finetune::race_anova()
8.66
Evaluate the model
8.67
Final evauation
8.68
Feature importance
8.69
Meeting Videos
8.69.1
Cohort 1
8.69.2
Cohort 2
8.69.3
Cohort 3
8.69.4
Cohort 4
8.69.5
Cohort 5
9
Support Vector Machines
9.1
Hyperplane
9.2
Separating Hyperplane
9.3
Maximal Margin Classifier
9.4
Mathematics of the MMC
9.5
Support Vector Classifiers
9.6
Mathematics of the SVC
9.7
Tuning Parameter
9.8
Nonlinear Classification
9.9
Support Vector Machines
9.10
Radial Kernels
9.11
SVM with Radial Kernels
9.12
More than Two Classes
9.13
Lab: Support Vector Classifier
9.13.1
Tuning
9.13.2
Linearly separable data
9.14
Meeting Videos
9.14.1
Cohort 1
9.14.2
Cohort 2
9.14.3
Cohort 3
9.14.4
Cohort 4
9.14.5
Cohort 5
10
Deep Learning
10.1
Introduction
10.2
Single Layer Neural Network
10.3
Lab: A Single Layer Network on the Hitters Data
10.4
Multilayer Neural Network
10.5
Convolutional Neural Network
10.6
Recurrent Neural Network
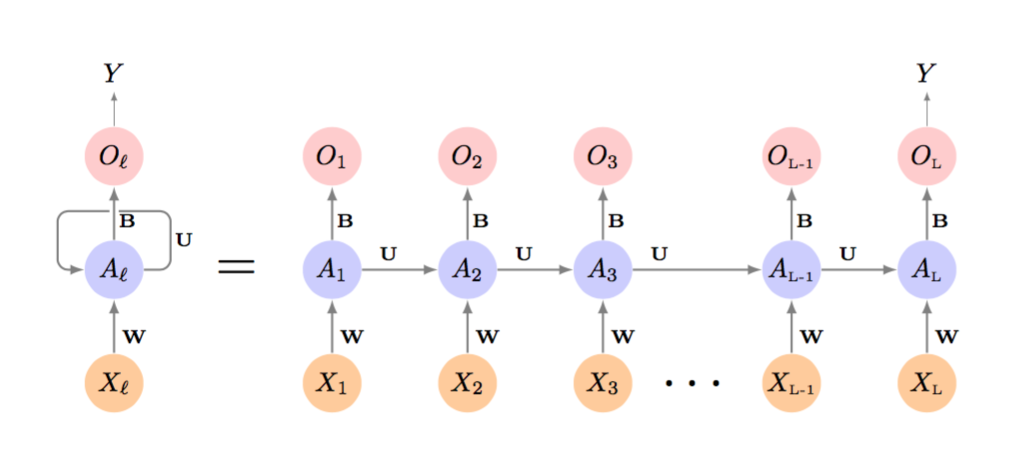
10.7
Backpropagation
10.8
Deep Learning part 2
10.9
Introduction
10.9.1
Multilayer neural networks
10.9.2
Convolutional Neural Networks (CNNs):
10.9.3
Recurrent Neural Networks (RNNs):
10.10
Case Study: RNN - Time Series
10.11
Meeting Videos
10.11.1
Cohort 1
10.11.2
Cohort 2
10.11.3
Cohort 3
10.11.4
Cohort 4
10.11.5
Cohort 5
11
Survival Analysis and Censored Data
11.1
What is survival data?
11.2
Introduction to Survival Analysis (zedstatistics) —
11.3
Censored Data
11.4
Lab: Brain Cancer survival analysis
11.5
Survival Function
11.6
Kaplan-Meier survival curve
11.7
Kaplan-Meier survival curve in R
11.8
KM curve stratified by sex
11.9
Log-Rank test
11.10
Survminer package
11.11
Hazard Function
11.11.1
How is the hazard rate related to the survival probability?
11.12
Regression models
11.13
Proportional Hazards
11.14
Cox Proportional Hazards Model
11.15
Surivival Curves
11.16
Additional Topics Covered in Text:
11.17
Conclusions
11.18
Meeting Videos
11.18.1
Cohort 1
11.18.2
Cohort 2
11.18.3
Cohort 3
11.18.4
Cohort 4
11.18.5
Cohort 5
12
Unsupervised Learning
12.1
Introduction
12.2
Principal component analysis
12.2.1
What are the steps to principal component analysis?
12.3
Geometric interpretation
12.4
Proportion of variance explained
12.5
The matrix decomposition
12.5.1
Matrix Completion
12.6
Clustering
12.7
K-means
12.8
Hierarchical clustering
12.8.1
Consideration on how to interpret Dendrogram results
12.9
References
Meeting Videos
12.9.1
Cohort 1
12.9.2
Cohort 2
12.9.3
Cohort 3
12.9.4
Cohort 4
12.9.5
Cohort 5
13
Multiple Testing
13.1
How to deal with more than one hypothesis test
13.2
Hypothesis testing steps
13.3
m NULL hypotheses
13.4
Family Wise Error Rate (FWER)
13.4.1
Controlling FWER
13.5
Power
13.6
False Discovery Rate (FDR)
13.7
Benjamini-Hochberg procedure
13.8
Case Study: Multiple hypothesis test in Genomics
13.9
Load libraries and datasets
13.10
Multiple T-test
13.10.1
FWER Family Wise Error Rate
13.10.2
FDR False discovery rate
13.11
Replications
13.12
Lab: Multiple Testing
13.13
The Family-Wise Error Rate
13.14
The False Discovery Rate
13.15
A Re-Sampling Approach
13.16
Meeting Videos
13.16.1
Cohort 1
13.16.2
Cohort 2
13.16.3
Cohort 3
13.16.4
Cohort 4
13.16.5
Cohort 5
Abbreviations
Appendix: Bookdown and LaTeX Notes
Markdown highlighting
Text coloring
Section references
Footnotes
Formatting Text
Figures
Displaying Formula
Formatting
Symbols
Notation
Equations
Basic Equation
Case-When Equation (Large Curly Brace)
Alligned with Underbars
Greek letters
Published with bookdown
Introduction to Statistical Learning Using R Book Club
10.7
Backpropagation
Figure 10.7: Backpropagation - youtube:
https://www.youtube.com/watch?v=Ilg3gGewQ5U