4.1 An Overview of Classification
Classification: Approaches to make inference and/or predict qualitative (categorical) response variable
Few common classification techniques (classifiers):
- logistic regression
- linear discriminant analysis (LDA)
- quadratic discriminant analysis (QDA)
- naive Bayes
- K-nearest neighbors
- Examples of classification problems:
- A person arrives at the emergency room with a set of symptoms that could possibly be attributed to one of three medical conditions. Which of the three conditions does the individual have?
- Predictor variable: Symptoms
- Response variable: Type of medical conditions
- An online banking service must be able to determine whether or not a transaction being performed on the site is fraudulent, on the basis of the user’s IP address, past transaction history, and so forth.
- Predictor variable: User’s IP address, past transaction history, etc
- Response variable: Fraudulent activity (Yes/No)
- On the basis of DNA sequence data for a number of patients with and without a given disease, a biologist would like to figure out which DNA mutations are deleterious (disease-causing) and which are not.
Predictor variable: DNA sequence data
Response variable: Presence of deleterious gene (Yes/No)
In the following section, we are going to explore the
Defaultdataset. The annual incomes (\(X_1\) =income) and monthly credit card balances (\(X_2\) =balance) are used to predict whether whether an individual will default on his or her credit card payment.
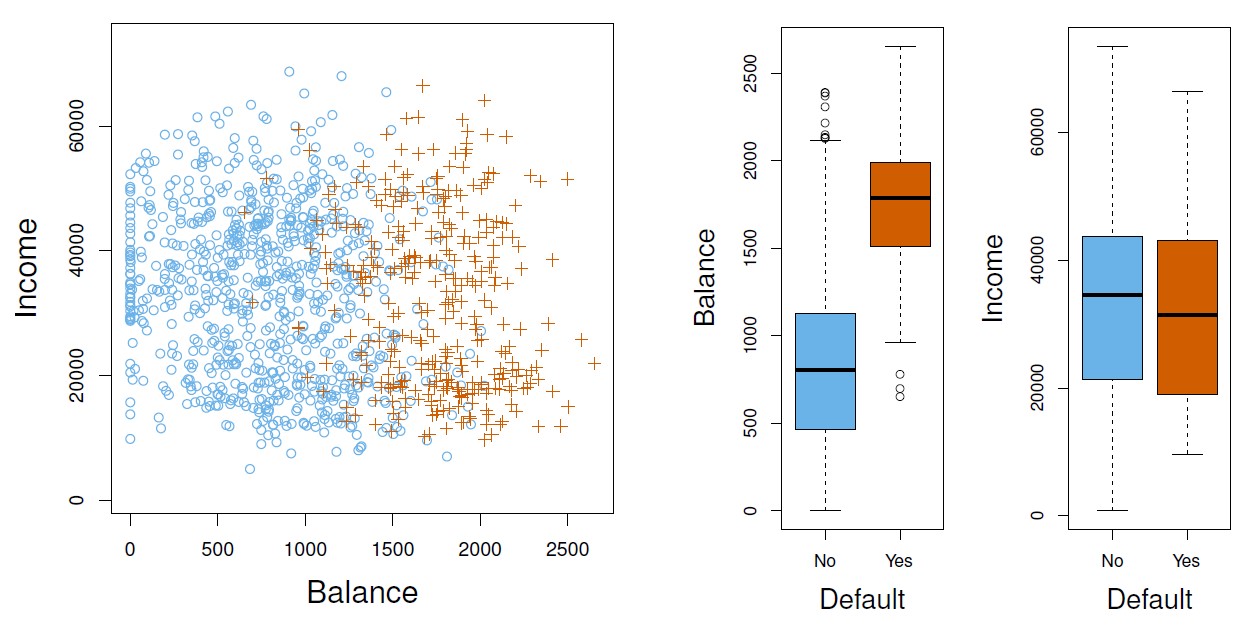
Figure 4.1: The distribution of balance and income split by the binary default variable respectively; Note. Defaulters represented as orange plus sign; non-defaulters represented as blue circle