Exercises
- What function would you use to read a file where fields were separated with “|”?
I would use
read_delim()and include the argumentdelim = '|''.
- Apart from file, skip, and comment, what other arguments do read_csv() and read_tsv() have in common?
col_names,col_types,col_select,id,locale,na,quoted_na,quote,comment,trim_ws,n_max,guess_max,progress,name_repair,num_threads,show_col_types,skip_empty_rows,lazy.
- What are the most important arguments to read_fwf()?
file,fwf_cols,fwf_positions,fwf_widths,fwf_empty
- Sometimes strings in a CSV file contain commas. To prevent them from causing problems, they need to be surrounded by a quoting character, like ” or ’. By default, read_csv() assumes that the quoting character will be “. To read the following text into a data frame, what argument to read_csv() do you need to specify?
quote = "''"to specify that we are using''as quotes in a string.
- Identify what is wrong with each of the following inline CSV files. What happens when you run the code?
## Warning: One or more parsing issues, call `problems()` on your data frame for details,
## e.g.:
## dat <- vroom(...)
## problems(dat)## Rows: 2 Columns: 2
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (1): a
## num (1): b
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 2 × 2
## a b
## <dbl> <dbl>
## 1 1 23
## 2 4 56read_csv("a,b,c\n1,2\n1,2,3,4") # Seems like they are missing a value in first row c, and there's an extra value in second row c. ## Warning: One or more parsing issues, call `problems()` on your data frame for details,
## e.g.:
## dat <- vroom(...)
## problems(dat)## Rows: 2 Columns: 3
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (2): a, b
## num (1): c
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 2 × 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 NA
## 2 1 2 34## Rows: 0 Columns: 2
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): a, b
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 0 × 2
## # ℹ 2 variables: a <chr>, b <chr>read_csv("a,b\n1,2\na,b") # second row has the same names as the column names, should they be numbers? ## Rows: 2 Columns: 2
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): a, b
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 2 × 2
## a b
## <chr> <chr>
## 1 1 2
## 2 a b## Rows: 1 Columns: 1
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (1): a;b
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 1 × 1
## `a;b`
## <chr>
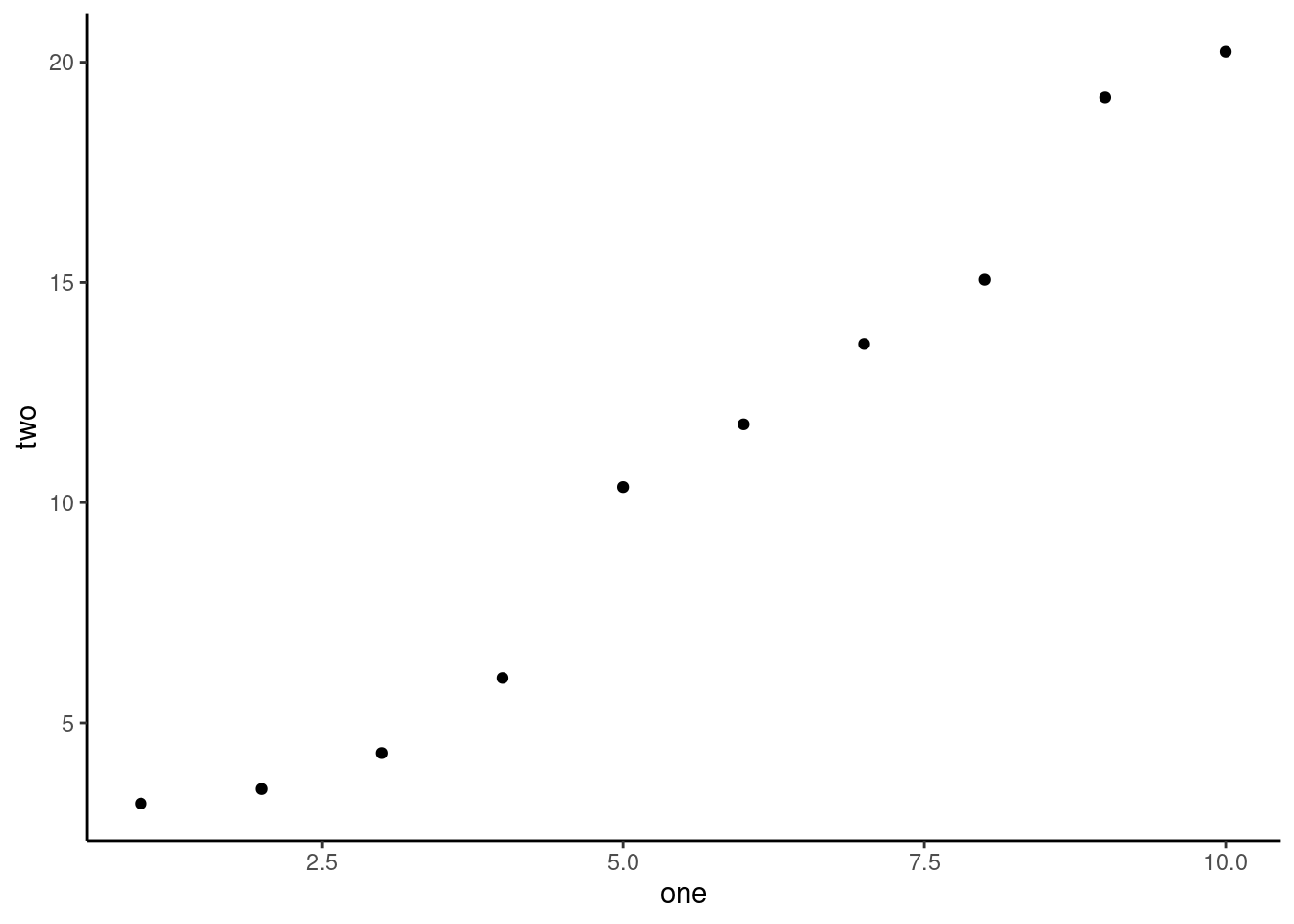
## 1 1;3Practice referring to non-syntactic names in the following data frame by:
- Extracting the variable called 1.
- Plotting a scatterplot of 1 vs. 2.
- Creating a new column called 3, which is 2 divided by 1.
- Renaming the columns to one, two, and three.
Here is my answer
clean <- annoying %>%
janitor::clean_names() %>%
rename(one = x1, two = x2) %>% # Rename columns
mutate(three = one/two) # Create a third column
clean_one <- clean %>% select(one) #Extract column one
# Scatterplot of columns one and two
ggplot(clean,
aes(x=one, y=two))+
geom_point()+
theme_classic()