13.4 Using atomic vectors
- Let’s review some of the important tools for working with the different types of atomic vectors:
- How to convert from one type to another, and when that happens automatically.
- How to tell if an object is a specific type of vector.
- What happens when you work with vectors of different lengths.
- How to name the elements of a vector.
- How to pull out elements of interest.
13.4.1 Coercion
- We can coerce or convert one type of vector to another in two ways:
Explicit coercion -> call a function like
as.logical(),as.integer(),as.double(), oras.character(). Before doing this, check the type of the vector. For example, you may need to tweak your readrcol_typesspecification.Implicit coercion -> use a vector in a specific context that expects a certain type of vector. For example, using a logical vector with a numeric summary function or using a double vector where an integer vector is expected.
- Our focus here will be implicit coercion as explicit coercion is relatively rarely used in data analysis plus easy to understand.
- An important type of implicit coercion: using a logical vector in a numeric context.
TRUEis converted to1andFALSEis converted to0. Hence, summing the logical vector is the # of trues and the mean of a logical vector is the proportion of trues.
x <- sample(20, 100, replace = TRUE)
y <- x > 10
sum(y) # how many are greater than 10?
mean(y) # what proportion are greater than 10?Or, some code that relies on implicit coercion in the opposite direction, from integer to logical:
Here, 0 is converted to FALSE and everything else is converted to TRUE. For easier understanding of the code, let’s be explicit: length(x) > 0.
NOTE1: When we create a vector containing multiple types with
c(): the most complex type always wins. –> Aha moment!
typeof(c(TRUE, 1L)) #integer wins
typeof(c(1L, 1.5)) #double wins
#why? Thinking here, because integer is created from a double?
typeof(c(1.5, "a")) #character winsNOTE2: An atomic vector can not only have a mix of different types since the type is a property of the complete vector, not the individual elements. For a mix of multiple types in the same vector, use a list.
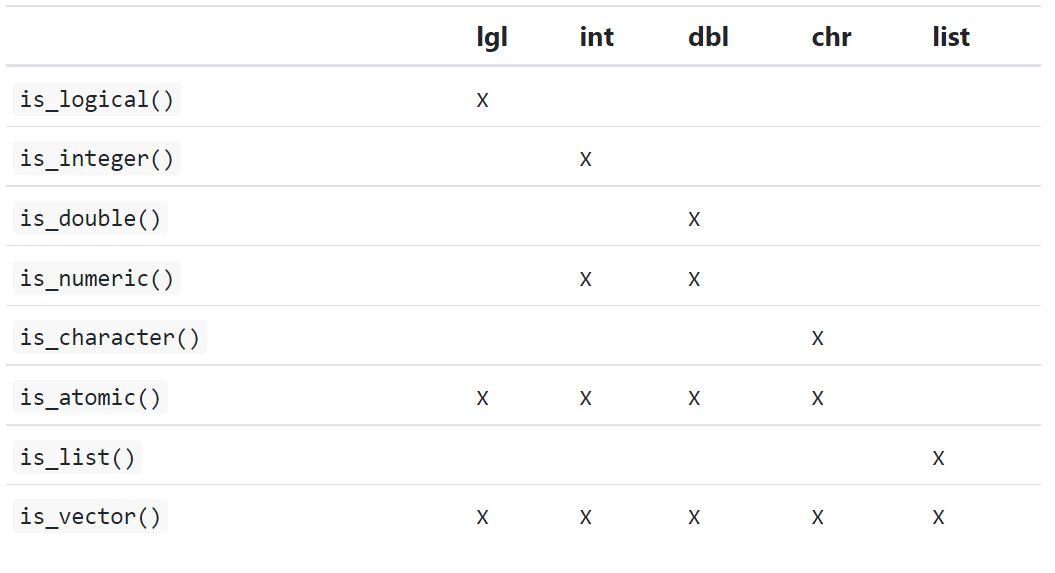
13.4.2 Test functions
- Suppose we want to have different things based on the type of vector:
- One option is to use
typeof(). - Or, use a test function which returns a
TRUEorFALSE.- Not recommended: base R functions ->
is.vector()andis.atomic(). - Instead let’s use the
is_*functions provided by purrr , summarised below.
- Not recommended: base R functions ->
- One option is to use
13.4.3 Scalars and recycling rules
- Not only does R implicitly coerce the types of vectors to be compatible, but it also implicitly coerce the length of vectors.
- This is called vector recycling because the shorter vector is repeated (or recycled) to the same length as the longer vector.
- Mostly useful when we are mixing vectors and “scalars”. Note, R doesn’t have scalars instead, a single number is a vector of length 1.
- Since there are no scalars, most built-in functions are vectorised meaning that they will operate on a vector of numbers. Hence, such a code will work:
- What happens if we add two vectors of different lengths?
R expands the shortest vector to the same length as the longest –> recycling.
But what if the length of the longer is not an integer multiple of the length of the shorter:
Vector recycling can silently conceal the problem, hence, the vectorised functions in tidyverse will throw errors when recycling anything other than a scalar. We can use rep() to do recycling ourselves.
13.4.4 Naming vectors
- We can name all types of vectors during creation with
c():
- Or, with
purrr::set_names():
Why name vectors? Because are useful in subsetting.
13.4.5 Subsetting
- To filter vectors, we use the subsetting function ->
[and is called likex[a].There are four types of things that you can subset a vector with:
- A numeric vector containing only integers, and these must either be all positive, all negative, or zero.
Subsetting with positive integers keeps the elements at those positions:
If we repeat a position, we can actually make a longer output than input:
Negative values drop the elements at the specified positions:
It’s an error to mix positive and negative values:
The error message mentions subsetting with zero, which returns no values:
This is useful if we want to create unusual data structures to functions with. (Jon, please expound!)
- Subsetting with a logical vector keeps all values corresponding to a
TRUEvalue; often useful in conjunction with the comparison functions.
x <- c(10, 3, NA, 5, 8, 1, NA)
# All non-missing values of x
x[!is.na(x)]
# All even (or missing!) values of x
x[x %% 2 == 0]- If you have a named vector, you can subset it with a character vector:
We can also use a character vector to duplicate individual entries.
- The simplest type of subsetting is nothing,
x[], which returns the completex. This is mostly useful when subsetting matrices (and other high dimensional structures) because we can select all the rows or all the columns, by leaving that index blank. E.g., ifxis 2d,x[1, ]selects the first row and all the columns.
Learn more about the applications of subsetting: “Subsetting” chapter of Advanced R: http://adv-r.had.co.nz/Subsetting.html#applications.
An important difference between [ and [[ -> [[ extracts only a single element, and always drops names. Use it whenever we want to make it clear that we’re extracting a single item, as in a for loop.
13.4.6 Exercises
- What does
mean(is.na(x))tell you about a vectorx? What aboutsum(!is.finite(x))?
mean(is.na(x)) calculates the proprtion of missing (NA) and not-a-number (NaN) values in a vector. The result of 0.286 is equal to 2 / 7 as expected.
sum(!is.finite(x)) calculates the number of elements in the vector that are equal to missing (NA), not-a-number (NaN), or infinity (Inf).
- Carefully read the documentation of
is.vector(). What does it actually test for? Why doesis.atomic()not agree with the definition of atomic vectors above?
is.vector() checks whether an object has no attributes other than names.
But any object that has an attribute apart from names is not:
is.atomic() explicitly checks whether an object is one of the atomic types (“logical”, “integer”, “numeric”, “complex”, “character”, and “raw”) or NULL.
is.atomic() will consider objects to be atomic even if they have extra attributes.
- Compare and contrast
setNames()withpurrr::set_names().
setNames() takes two arguments, a vector to be named and a vector of names to apply to its elements.
set_names() has more ways to set names than setNames(). We can specify the names the same way as setNames():
The names can also be specified as unnamed arguments:
set_names() will name an object with itself if no nm argument is provided (the opposite of setNames() behavior).
The main difference between set_names() and setNames() is that set_names() allows for using a function or formula to transform the existing names.
purrr::set_names(c(a = 1, b = 2, c = 3), toupper)
purrr::set_names(c(a = 1, b = 2, c = 3), ~toupper(.))set_names() function also checks that the length of the names argument is the same length as the vector that is being named, and will raise an error if it is not.
setNames() function will allow the names to be shorter than the vector being named, and will set the missing names to NA.
Create functions that take a vector as input and returns:
The last value. Should you use
[or[[?The elements at even numbered positions.
Every element except the last value.
Only even numbers (and no missing values).
Why is
x[-which(x > 0)]not the same asx[x <= 0]?What happens when you subset with a positive integer that’s bigger than the length of the vector? What happens when you subset with a name that doesn’t exist?