5.1 Spending our data
The task of creating a useful model can be daunting. Thankfully, one can do so step-by-step. It can be helpful to sketch out your path, as Chanin Nantasenamat has done so:
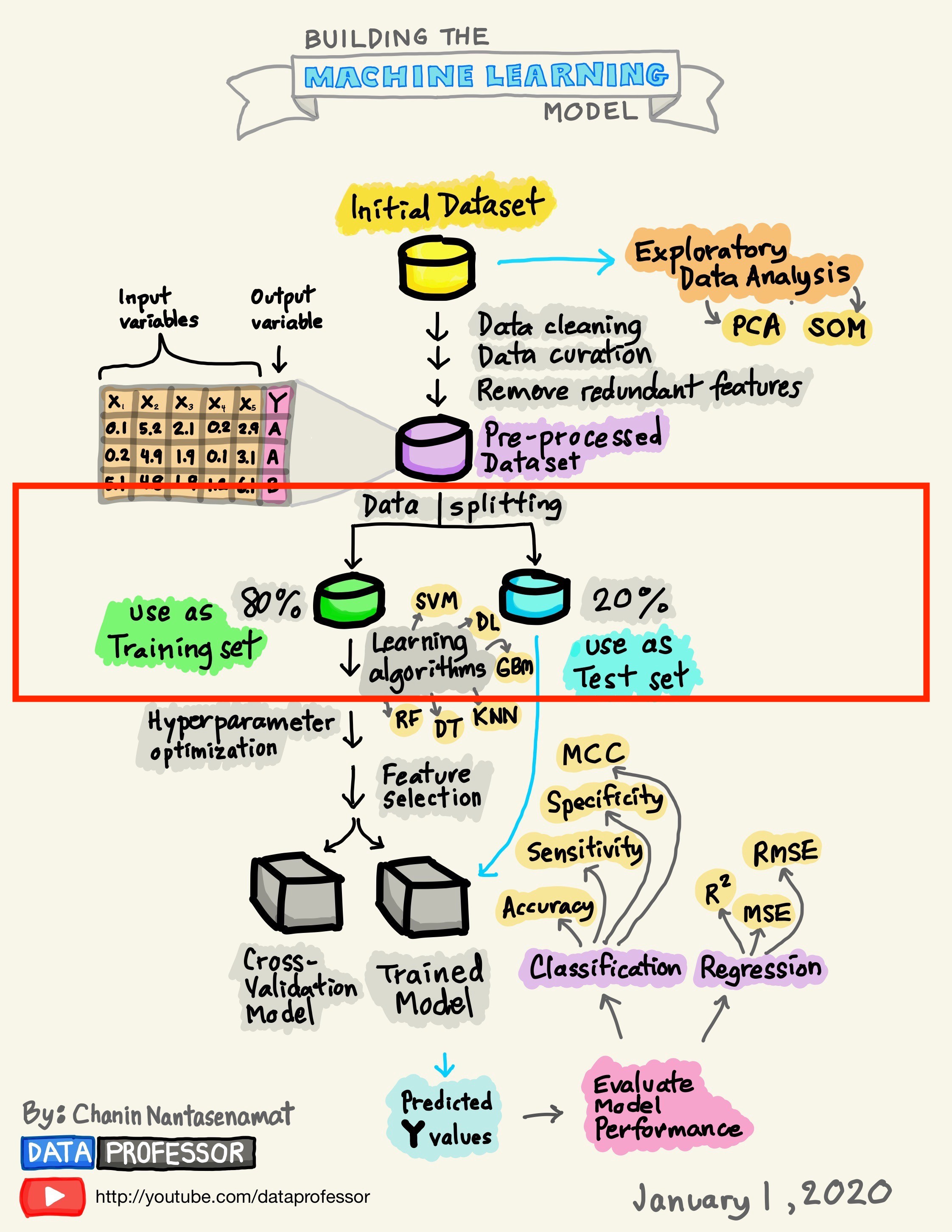
We’re going to zoom into the data splitting part. As the diagram shows, it is one of the earliest considerations in a model building workflow. The training set is the data that the model(s) learns from. It’s usually the majority of the data (~ 80-70% of the data), and you’ll be spending the bulk of your time working on fitting models to it.
The test set is the data set aside for unbiased model validation once a candidate model(s) has been chosen. Unlike the training set, the test set is only looked at once.
Why is it important to think about data splitting? You could do everything right, from cleaning the data, collecting features and picking a great model, but get bad results when you test the model on data it hasn’t seen before. If you’re in this predicament, the data splitting you’ve employed may be worth further investigation.