10.6 A case study
Incorrectly combining feature selection and resampling
Goal: identify a subset of predictors with 80% accuracy
- 75 samples from each of the two classes
- 10,000 predictors for each data point
- 70% of the data for a training set
- 10-fold cross-validation for model training
- implicit feature selection methods of the glmnet and random forest.
Initial results:
- 60% best cross-validation accuracy
First adjustments approach that resulted in worst results:
- PCA for reducing dimensions
- linear discriminant analysis
- partial least squares discriminant analysis
Second adjustments approach:
first identify and select predictors that had a univariate signal with the response
- t-test performed for each predictors
- predictors rank by significance
- top 300 predictors selected for modeling
- PCA on the 300 predictors
- plotted first two components colored by response category
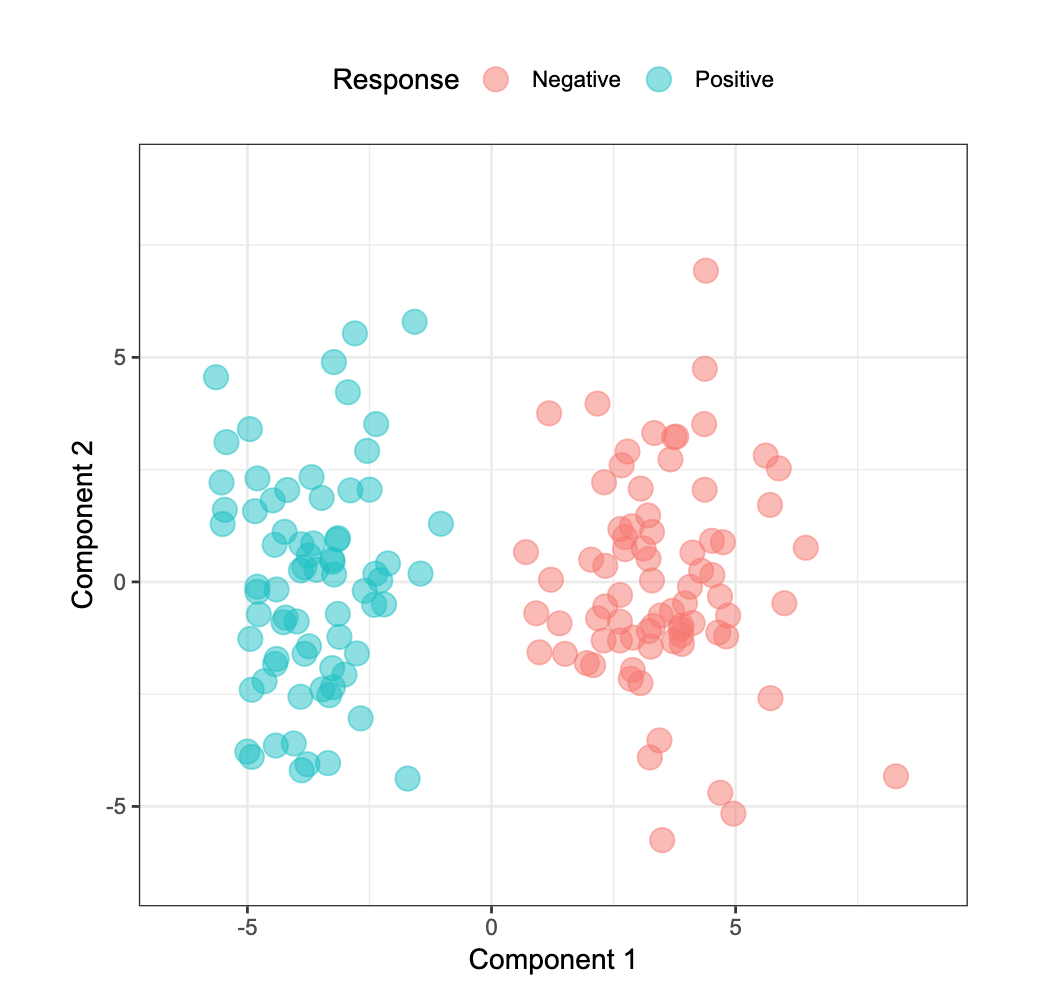
Figure 10.3: First two components obtained with: feature selection outside of resampling
This second method provided a clear answer, showing a complete separation of the components.