5.6 Actual prediciting k (model tuning)
## PREDICT K ON TRAINING DATA
set.seed(101)
k=1:12 # set k values
trainErr=c() # set vector for training errors
for( i in k){
knnFit=knn3(x=training[,-1], # training set
y=training[,1], # training set class labels
k=i)
# predictions on the training set
class.res=predict(knnFit,training[,-1],type="class")
# training error
err=1-confusionMatrix(training[,1],class.res)$overall[1]
trainErr[i]=err
}
# plot training error vs k
plot(k,trainErr,type="p",col="#CC0000",pch=20)
# add a smooth line for the trend
lines(loess.smooth(x=k, trainErr,degree=2),col="#CC0000")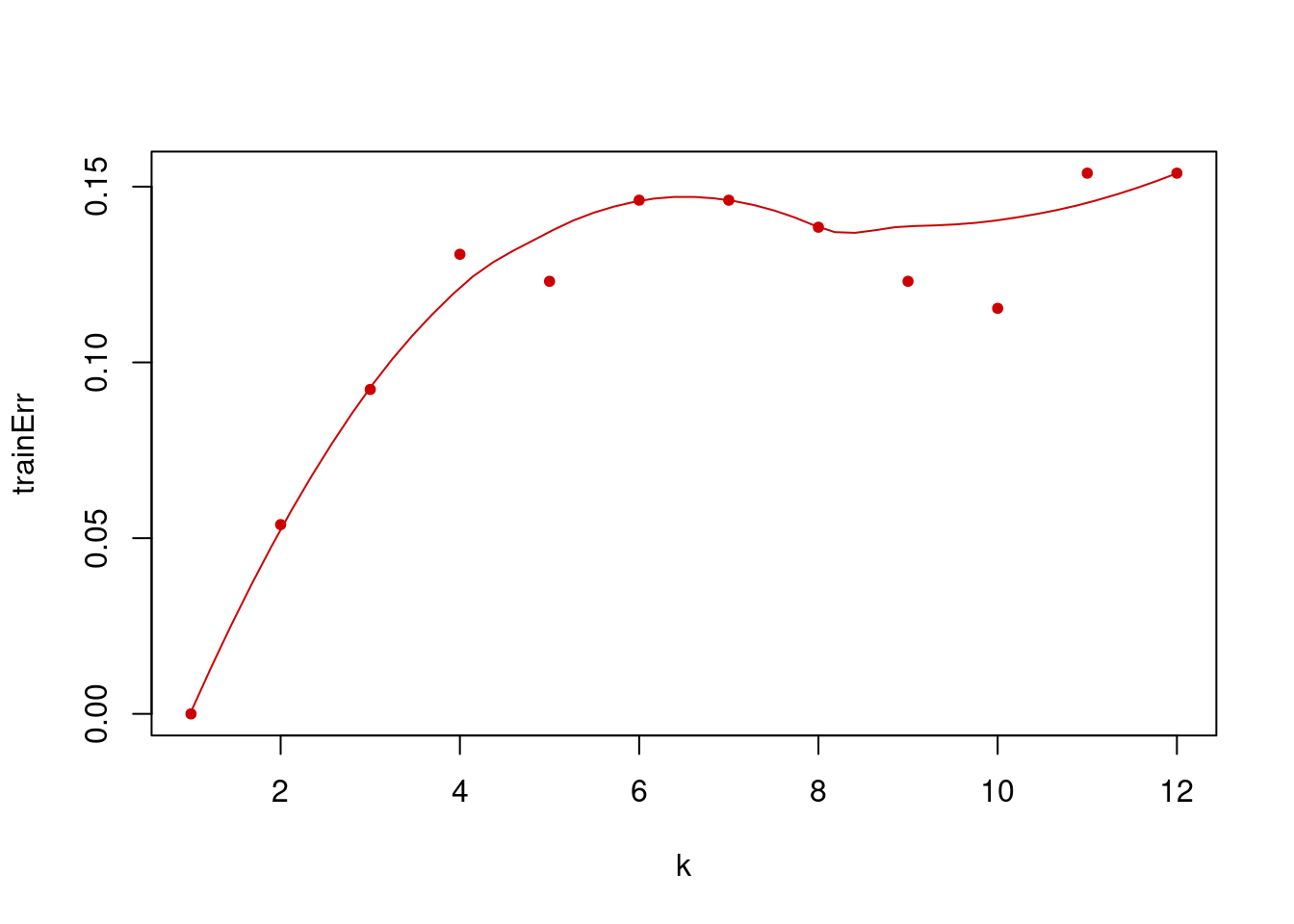
set.seed(31)
k=1:12
testErr=c()
for( i in k){
knnFit=knn3(x=training[,-1], # training set
y=training[,1], # training set class labels
k=i)
# predictions on the training set
class.res=predict(knnFit,testing[,-1],type="class")
testErr[i]=1-confusionMatrix(testing[,1],
class.res)$overall[1]
}
# plot training error
plot(k,trainErr,type="p",col="#CC0000",
ylim=c(0.000,0.08),
ylab="prediction error (1-accuracy)",pch=19)
# add a smooth line for the trend
lines(loess.smooth(x=k, trainErr,degree=2), col="#CC0000")
# plot test error
points(k,testErr,col="#00CC66",pch=19)
lines(loess.smooth(x=k,testErr,degree=2), col="#00CC66")
# add legend
legend("bottomright",fill=c("#CC0000","#00CC66"),
legend=c("training","test"),bty="n")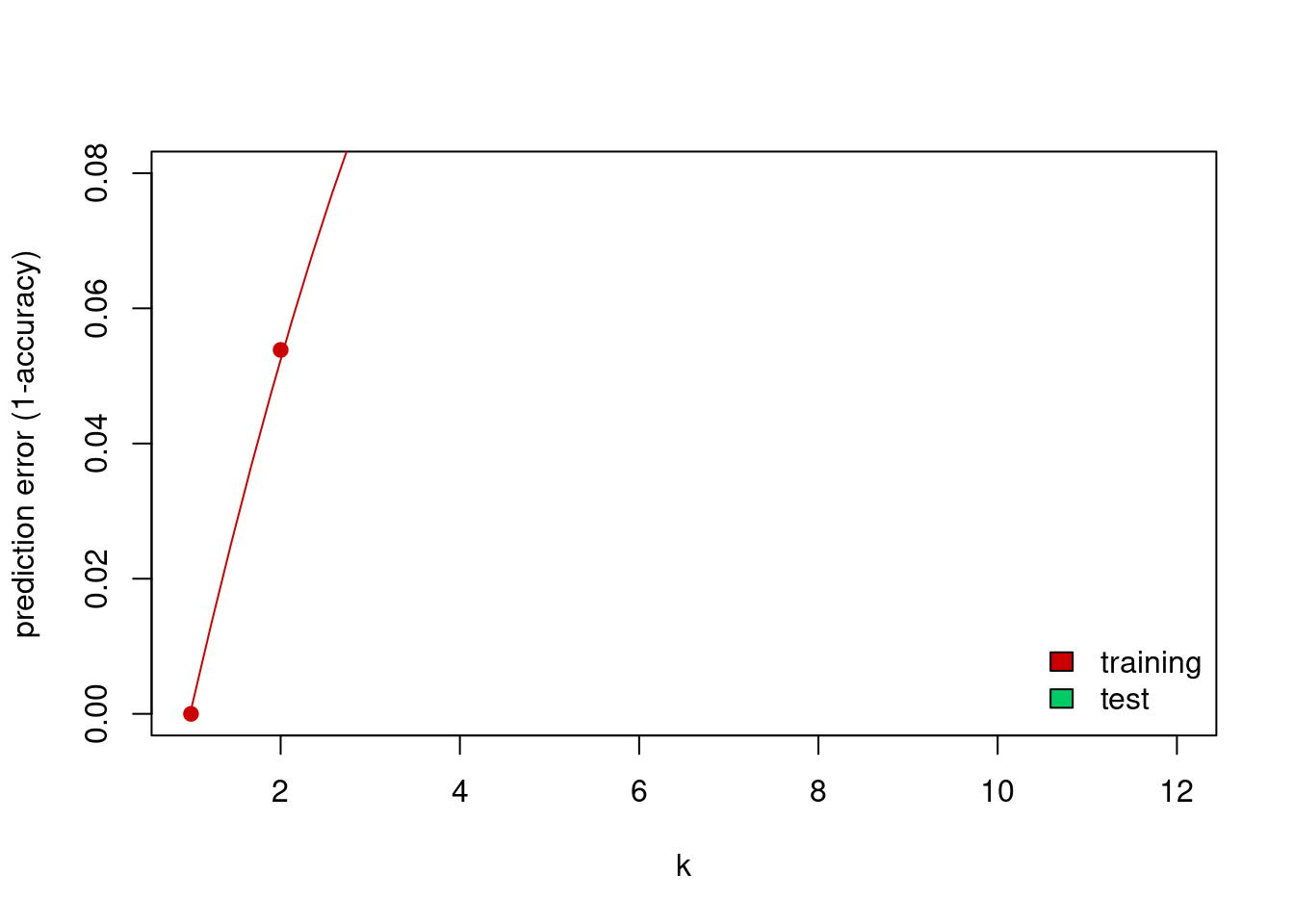
Want to have the happy medium between model complexity and prediction error…
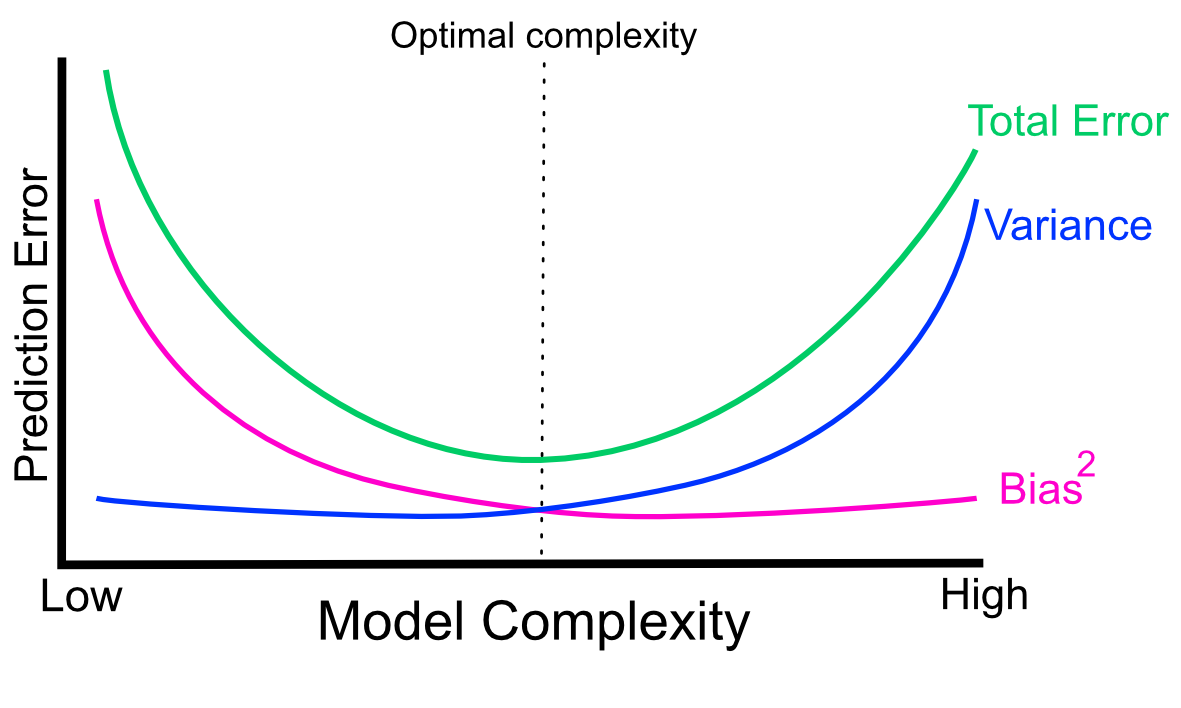
Predicition error vs model complexity. Source: https://compgenomr.github.io/book/model-tuning-and-avoiding-overfitting.html
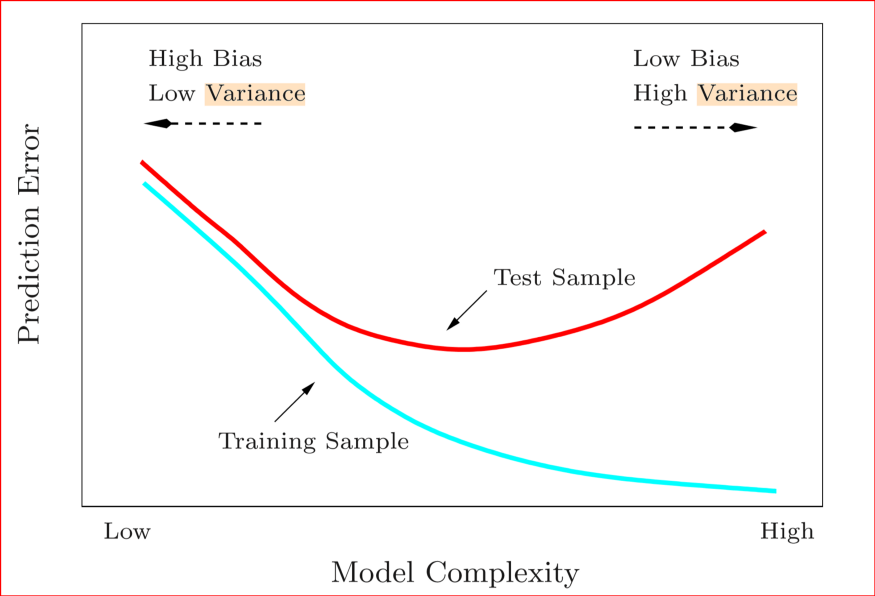
Predicition error vs model complexity. Source: https://compgenomr.github.io/book/model-tuning-and-avoiding-overfitting.html
set.seed(17)
# this method controls everything about training
# we will just set up 10-fold cross validation
trctrl <- trainControl(method = "cv",number=10)
# we will now train k-NN model
knn_fit <- train(subtype~., data = training,
method = "knn",
trControl=trctrl,
tuneGrid = data.frame(k=1:12))
# best k value by cross-validation accuracy
knn_fit$bestTune## k
## 1 1# plot k vs prediction error
plot(x=1:12,1-knn_fit$results[,2],pch=19,
ylab="prediction error",xlab="k")
lines(loess.smooth(x=1:12,1-knn_fit$results[,2],degree=2),
col="#CC0000")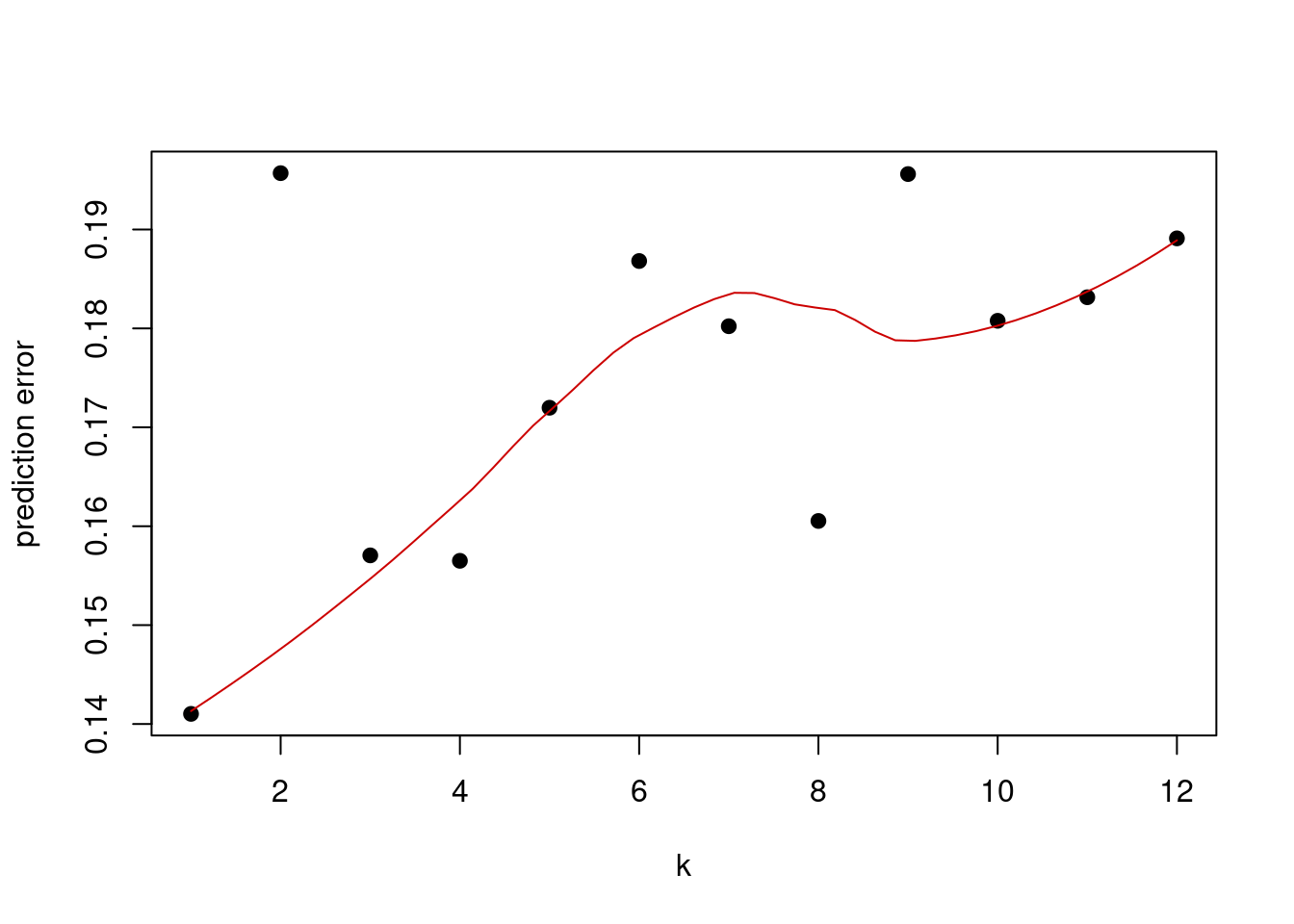
Another strategy for model tuning: Permutation of variables in the test phase – which variables are important?