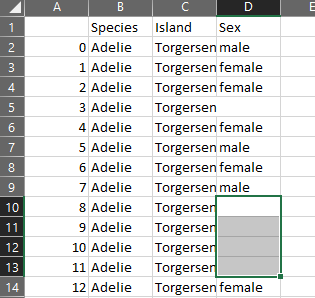
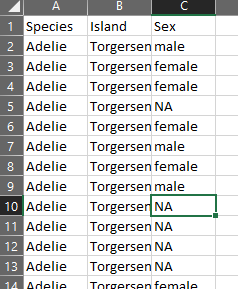
[('Atlanta', 'Georgia', 1.25, 6),
('Seattle', 'Washington', 2.6, 3),
('Sacramento', 'California', 1.7, 5),
('Atlanta', 'Georgia', 1.25, 6),
('Seattle', 'Washington', 2.6, 3),
('Sacramento', 'California', 1.7, 5),
('Atlanta', 'Georgia', 1.25, 6),
('Seattle', 'Washington', 2.6, 3),
('Sacramento', 'California', 1.7, 5),
('Atlanta', 'Georgia', 1.25, 6),
('Seattle', 'Washington', 2.6, 3),
('Sacramento', 'California', 1.7, 5),
('Atlanta', 'Georgia', 1.25, 6),
('Seattle', 'Washington', 2.6, 3),
('Sacramento', 'California', 1.7, 5),
('Atlanta', 'Georgia', 1.25, 6),
('Seattle', 'Washington', 2.6, 3),
('Sacramento', 'California', 1.7, 5),
('Atlanta', 'Georgia', 1.25, 6),
('Seattle', 'Washington', 2.6, 3),
('Sacramento', 'California', 1.7, 5)]