31. LLMs for Synthetic Data
Ch 31: LLMs for Synthetic Data (10 min)
Original Google Slides (well-formatted) Quarto version may have some slides missing or poorly formatted
“ Synthetic data __ are artificially generated rather than produced by real-world events. Typically created using algorithms … __ .” - Wikipedia
Distillation - Distillation is a technique in LLM training where a smaller, more efficient “student” model is trained to mimic the behavior and knowledge of a larger, more complex “teacher” model. ( Datacamp )
Basically, using the inputs to and outputs from a trained LLM as training data for another LLM.
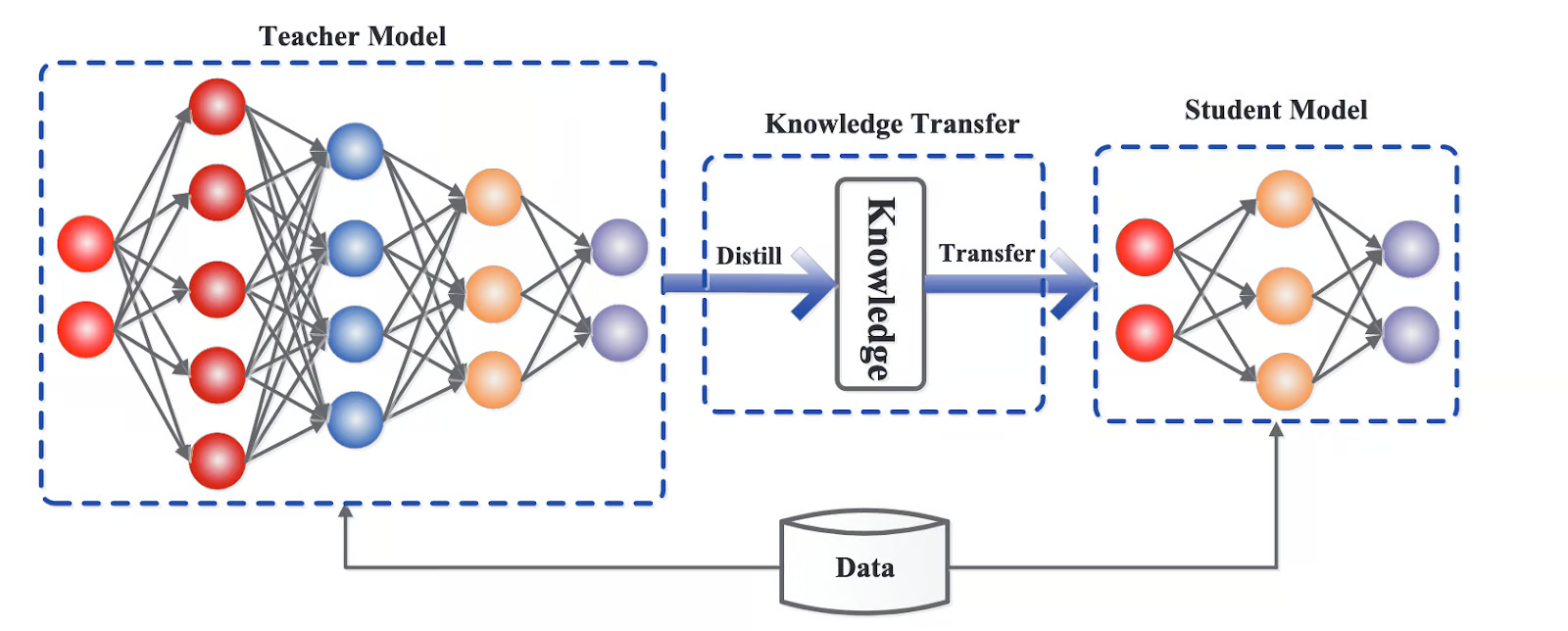
Distillation - Distillation is a technique in LLM training where a smaller, more efficient “student” model is trained to mimic the behavior and knowledge of a larger, more complex “teacher” model. ( Datacamp )
Basically, using the inputs to and outputs from a trained LLM as training data for another LLM.
Advantages :
Small, fast models. Train and inference with less computation, sometimes on more resource-constrained hardware.
Disadvantages :
Copyright issues. Simpler student model. Knowledge loss from teacher models.
Distillation Methods
Knowledge Distillation __ - The teacher models output token probability distribution and ground truth label, for each output, is used to train __ the __ student model. The teacher models output probabilities are known as __ soft targets , and allow __ the student a nuanced information about all possible outputs instead of a single correct answer. The teacher models ground truth labels are known as __ hard targets , and provide a single correct answer. Both the soft and hard targets are used to train the student model.
Most important technique.
Other Distillation Methods
Data Augmentation __ - Using the teacher models input and output generated data as the training data for the student model to train on. This allows student to be trained on a broader range of examples, and critical cases, improving student model generalization to other cases.__
Intermediate layer distillation __ - Transfer knowledge from the teacher models middle layers, instead of outputs. So the student can receive more detailed structural knowledge instead of just the final output.__
Multi-teacher distillation __ - Knowledge from multiple teacher models is used to train the student model, allowing the student to receive and integrate an aggregation of different knowledge.__
Distillation Example: Allegations that Deepseek R1 was distilled from OpenAI ChatGPT, in violation of OpenAI’s terms and conditions.
Ironically, OpenAI’s Chat GPT __ was trained on large amounts of internet content which may have been in violation of those __ contents’ __ terms and conditions.__
And DeepSeek R1 is open source while OpenAI ChatGPT is closed source.
DeepSeek R1 release __ page advertises “⚡ Performance on par with OpenAI-o1” and usage screenshots indicate Deepseek claims to be ChatGPT__
Similar performance using much less money and computation, and trained on worse hardware.


Reinforcement learning from AI feedback (RLAIF) __ - Machine learning technique in which AI models provide feedback to other AI models during the reinforcement learning process.__
Reinforcement Learning from Human Feedback (RLHF) __ - Machine learning technique in which a human rater assesses an AI model’s performance through reinforcement learning.__
| Feature | RLHF (Reinforcement Learning from Human Feedback) | RLAIF (Reinforcement Learning from AI Feedback) |
|---|---|---|
| Feedback Source | Human annotators | Existing AI models (e.g., LLMs) |
| Scalability | Limited by the availability and cost of human labor | Highly scalable due to automation |
| Feedback Quality | High potential for capturing nuanced human preferences | Dependent on the capabilities of the AI model providing feedback |
| Cost | Can be expensive due to the need for human labor | Potentially more cost-effective due to automation |
| Speed | Slower due to the time required for human annotation | Faster due to automated feedback generation |
| Bias | Can be subject to human biases | Can inherit biases from the AI model providing feedback |
“__ Synthetic data __ are artificially generated rather than produced by real-world events. Typically created using algorithms … .” - Wikipedia
Dai et al. (2022) proposed a method … with only 8 manually labeled examples and a large corpus of unlabeled data … can achieve a near State-of-the-Art performance. This research confirms that synthetically generated data facilitates training task-specific retrievers for tasks where supervised in-domain fine-tuning is a challenge due to data scarcity.
Model Collapse - When machine learning models degrade due to training on the outputs of another model, including prior versions of itself. Such outputs are known as synthetic data.
Model collapse can occur because of functional approximation errors, sampling errors, and learning errors. Importantly, it happens in even the simplest of models, where not all of the error sources are present. In more complex models the errors often compound, leading to faster collapse.