29. Retrieval-Augmented Generation
Retrieval-Augmented Generation
RAG is an application pattern for LLMS.
It uses information retrieval systems to give LLMs extra context.
Allows the LLM to answer user queries not covered in its training data
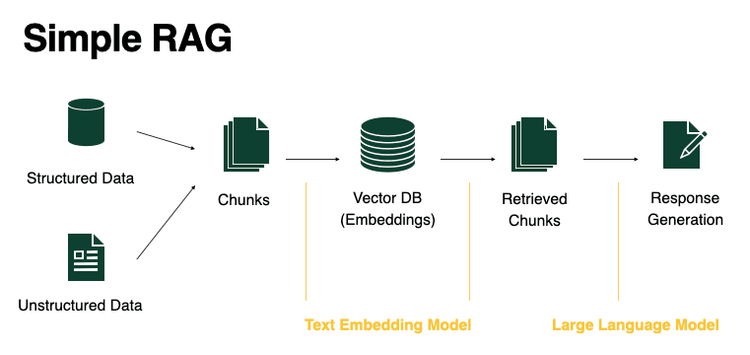
RAG
Query construction
Where does the data live? what syntax is needed to query the data?
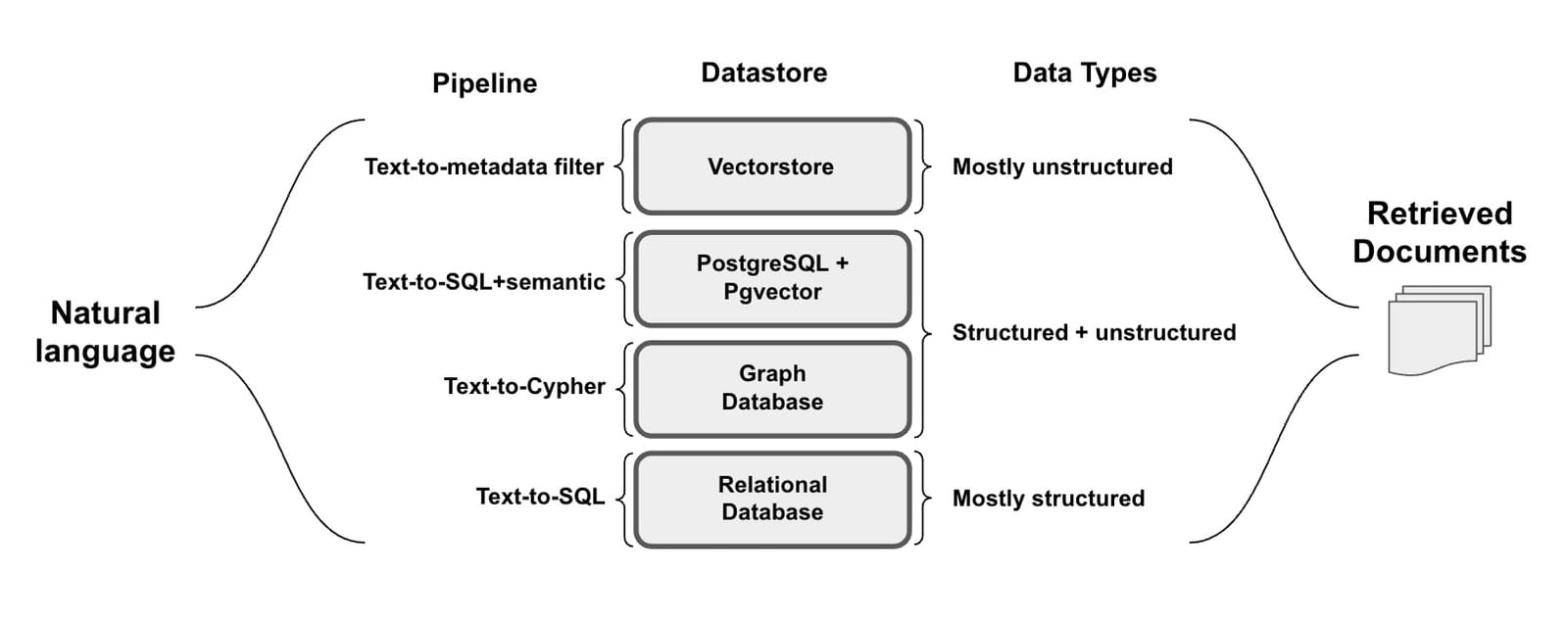
Query construction
In production RAG systems are a group of AI models, each playing its part in the workflow of data processing and response generation.
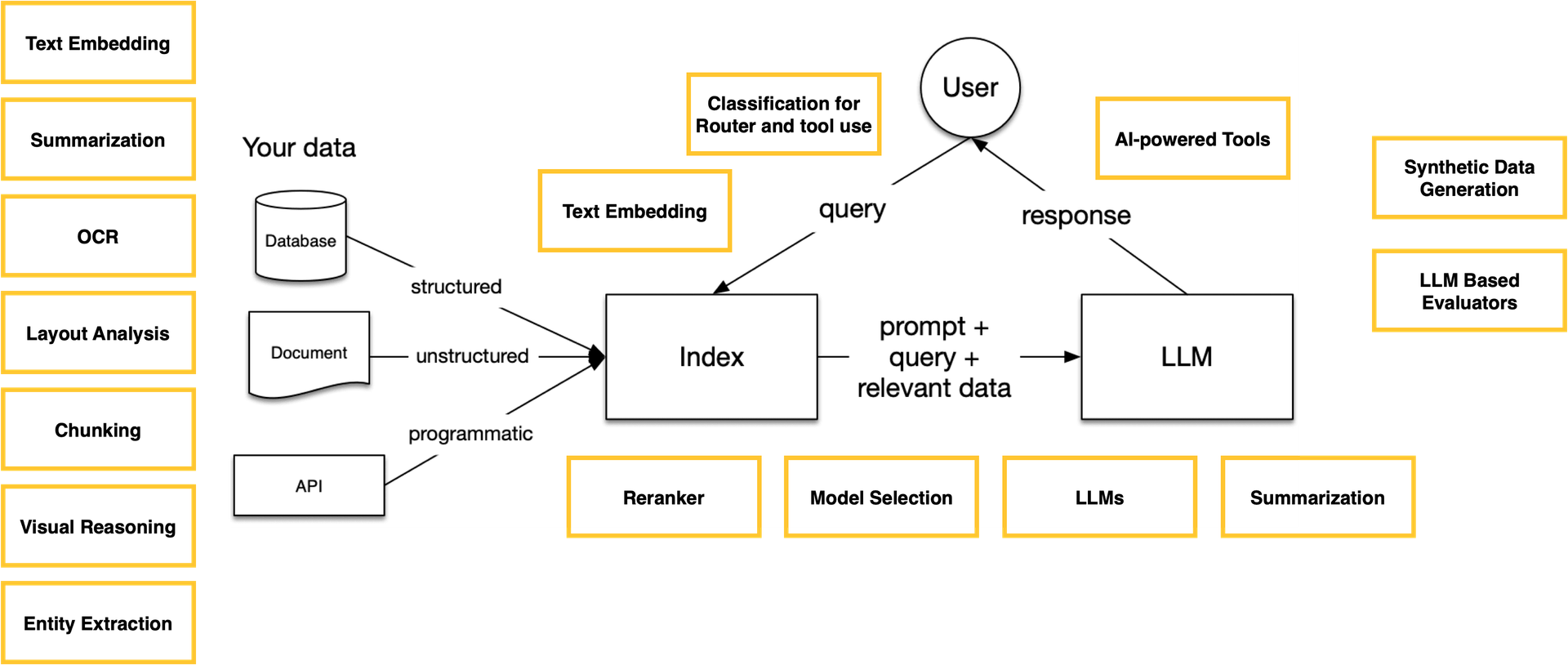
RAG systems