28. Vector Databases and Reranking
Vector databases
Vector databases facilitate semantic search on your data.
- Embedding models return vectors and LLM understand context from those vectors.
- Used for Retrieval-Augmented Generation systems to query documents.
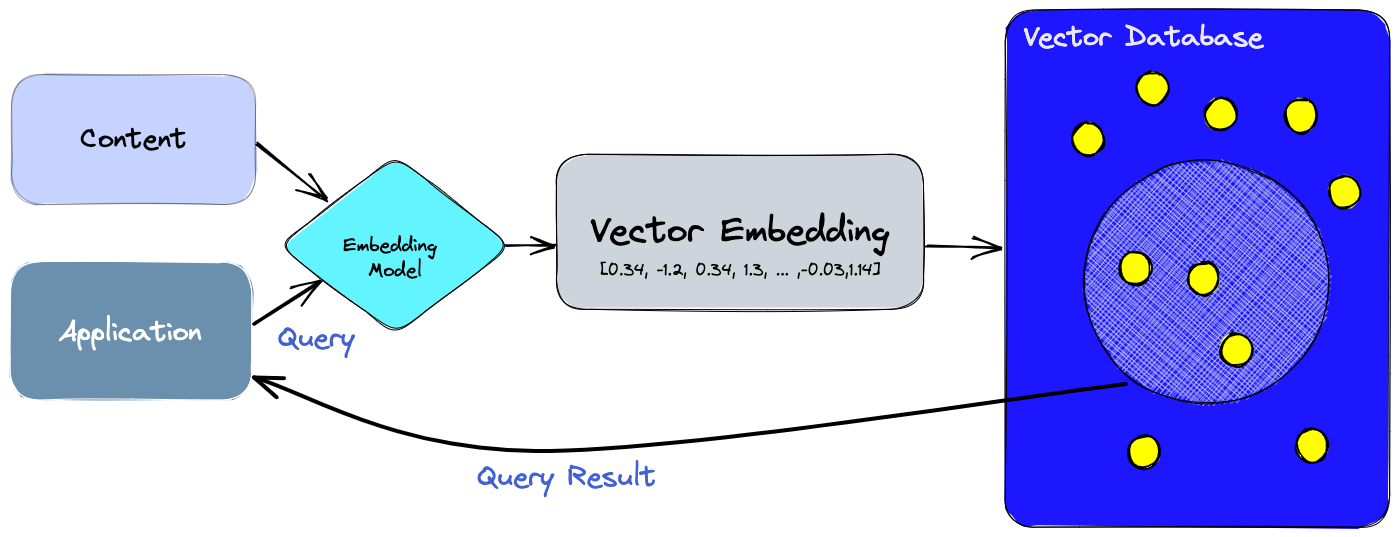
Vector database
Some popular vector databases

Vector databases
Retrieval Augmented Generation (RAG) is more than putting documents into a vector DB and adding an LLM on top.
- Recall: how many of the relevant documents are we retrieving.
- LLM recall : the ability of an LLM to find information from the text placed within its context window (its RAM).
- More tokens in the context window, less LLM recall.
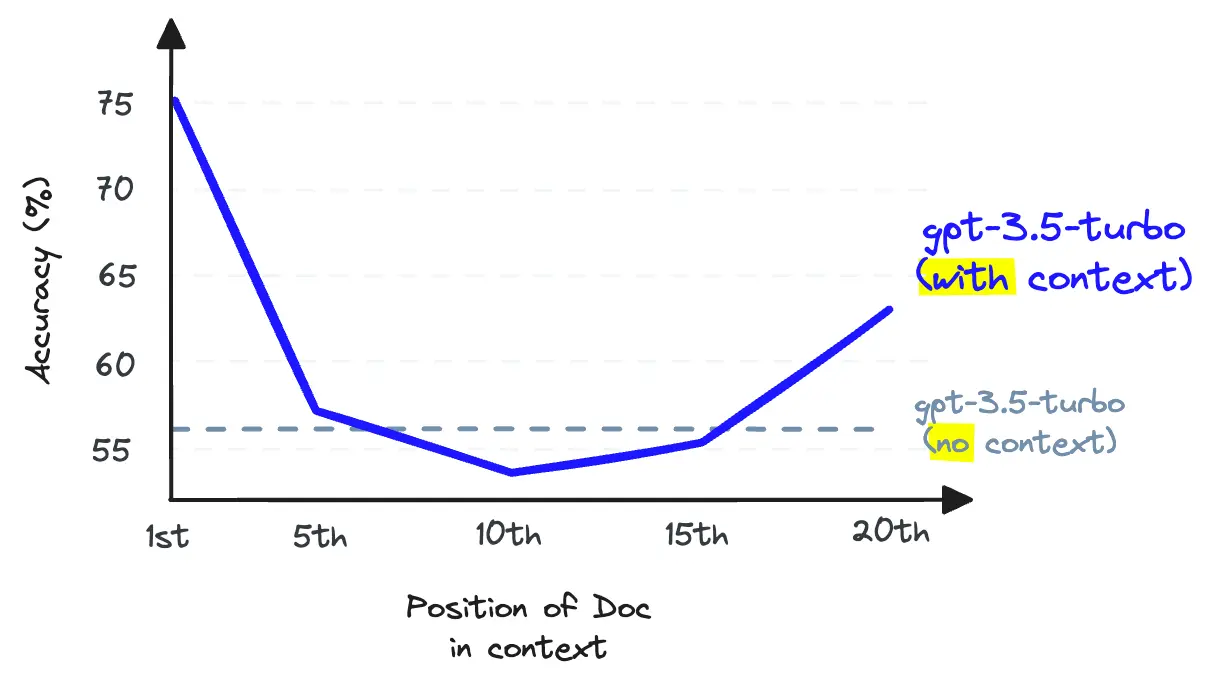
Recall and context window
Maximize retrieval recall by retrieving plenty of documents and then maximize LLM recall by minimizing the number of documents that make it to the LLM
Solution: Reranker model
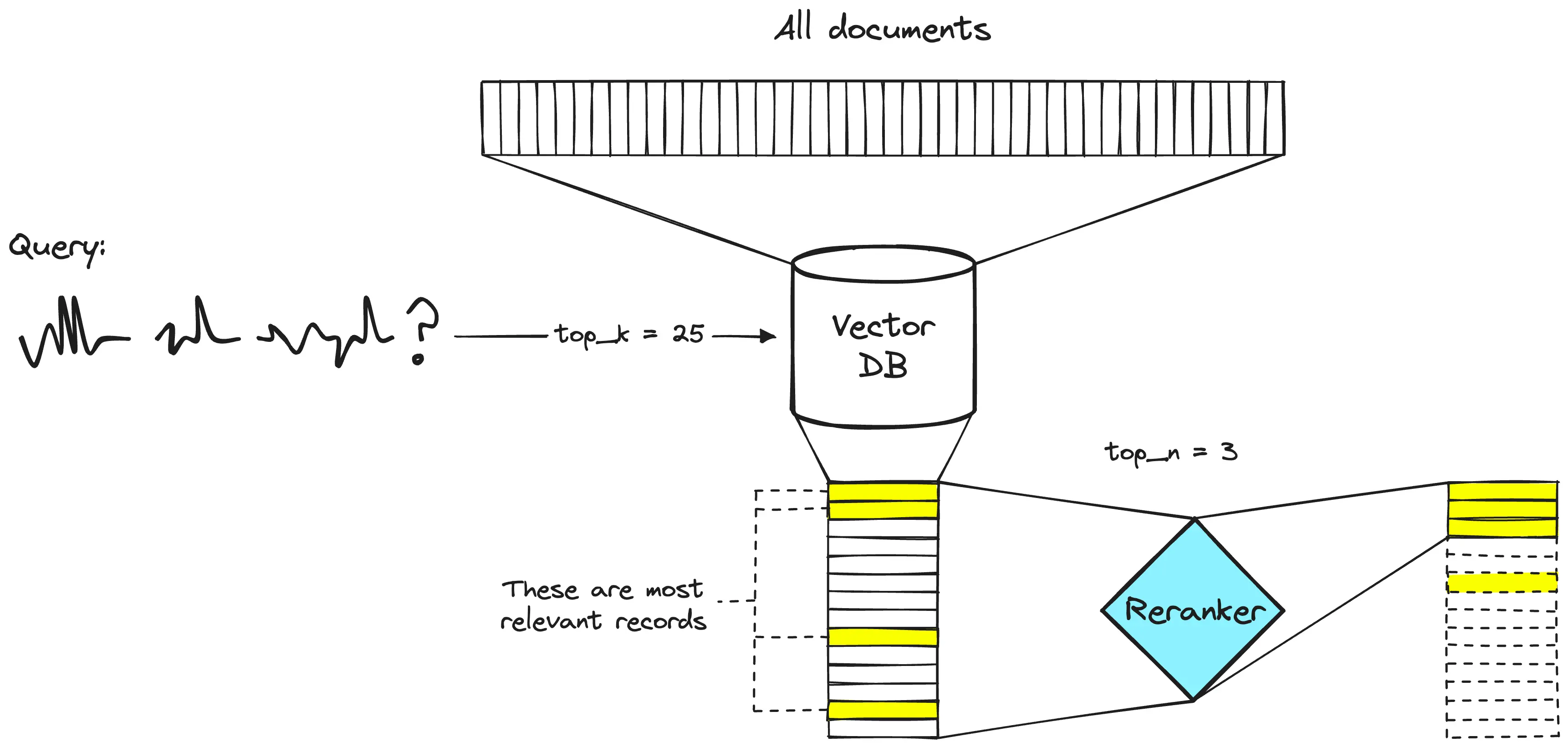
Reranker