27. Prompting Techniques
- Instruction prompting: Finetune technique on a pretrained model.
- Instructed LM Training with tuples of (
task instruction,input,ground truth output) - RLHF (Reinforcement Learning from Human Feedback) is a common method.
- It improves the model to be more aligned with human intention.
- Instructed LM Training with tuples of (
Instruction prompting
Other techniques
- Self-Ask: Prompt the model to ask following-up to build the thought process iteratively.
- IRCoT (Interleaving Retrieval CoT) and ReAct (Reason + Act) combine iterative CoT prompting with queries to Wikipedia APIs to add to the context.
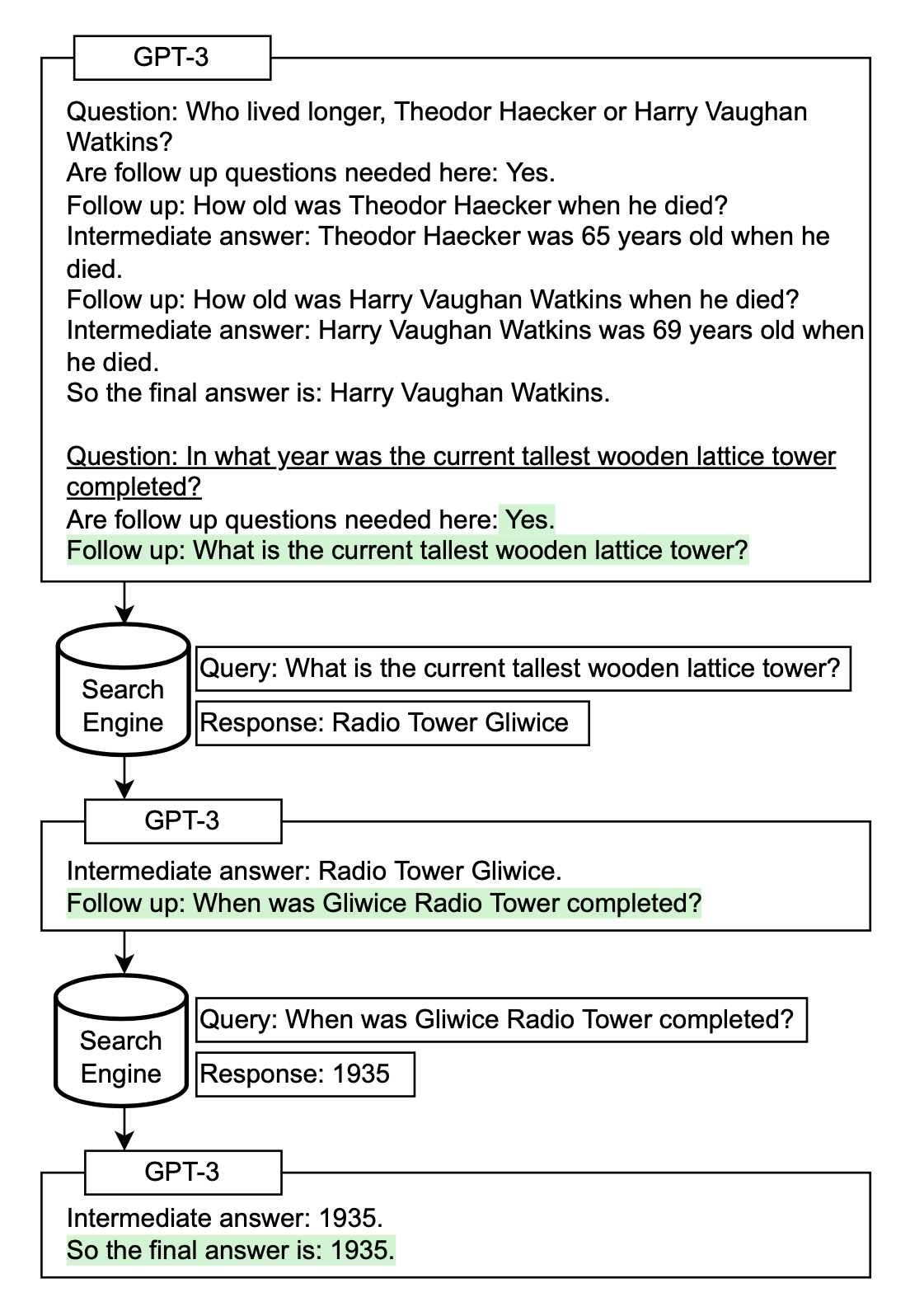
Other examples
- PAL (Program-aided language models; Gao et al. 2022) and PoT (Program of Thoughts prompting; Chen et al. 2022): ask LLM to generate programming language statements.

PoT
- TALM (Tool Augmented Language Models; Parisi et al. 2022): model augmented with text-to-text API calls. It builds API requests and calls them to append the result.
![TALM]()
