26. Sampling and Structured Outputs
Why is sampling important?
LLMs don’t directly produce text.
They calculate logits: scores assigned to every possible token.

Logits in LLMS
How do these probabilities generate text? With decoding methods
Greedy search
It takes the most probable token at each step as the next token in the sequence.
It discard all other potential options.
It can miss out on better overall sequences.
Step 1: Input: I have a dream → ” of”
Step 2: Input: I have a dream of → ” being”
Step 3: Input: I have a dream of being → ” a”
Step 4: Input: I have a dream of being a → ” doctor”
Step 5: Input: I have a dream of being a doctor → “.”
Generated text: I have a dream of being a doctor.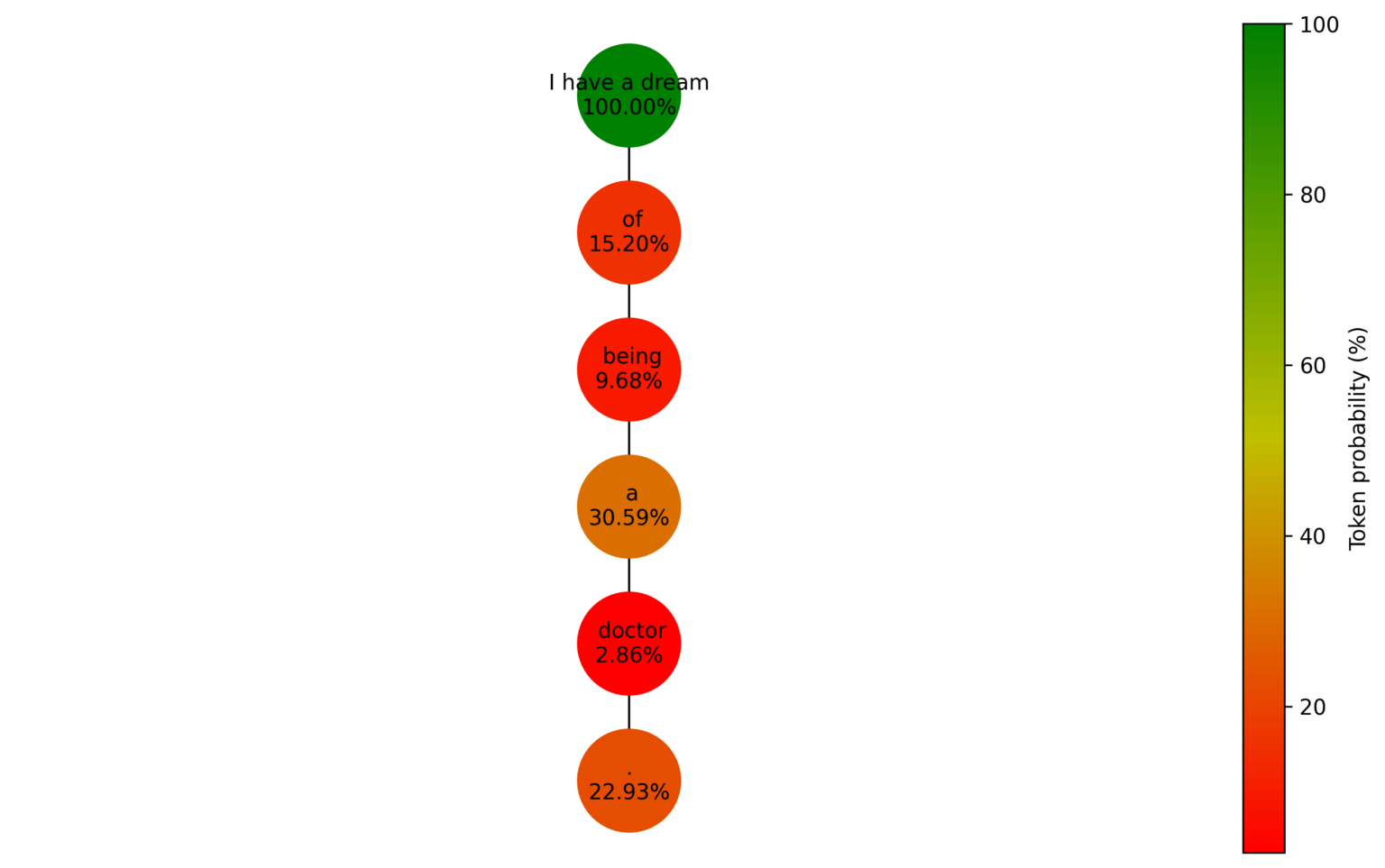
Beam search
It takes the n most likely tokens (number of beams)
It repeats until max length or end-of-sequence token

Beam decoding
It chooses the beam or sequence with the highest overall score.
Generated text: I have a dream. I have a dreamTop-k sampling
It uses the probability distribution to select a token from the k most likely options.
It introduces randomness in the selection process.
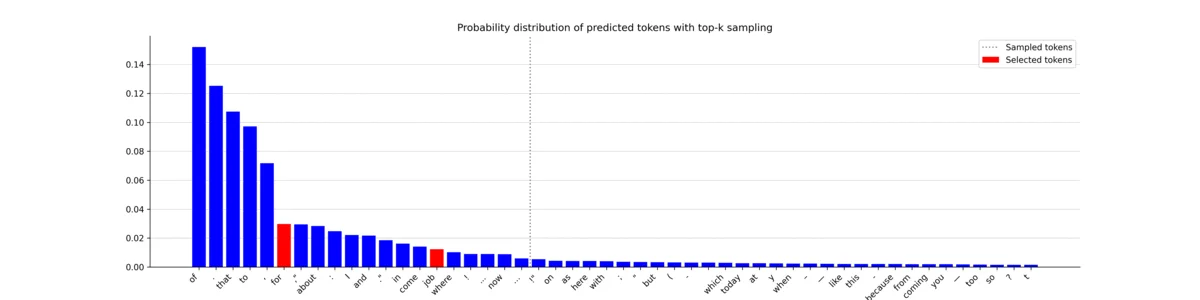
Top-k distribution
It can use the temperature parameter
Top-k sampling

Top-k
Generated text: I have a dream job and I want toNucleus sampling or Top-p sampling
It chooses a cutoff value p such as the sum of the probabilities of the selected tokens exceeds p.
It forms a nucleus of tokens from which to randomly choose the next token.
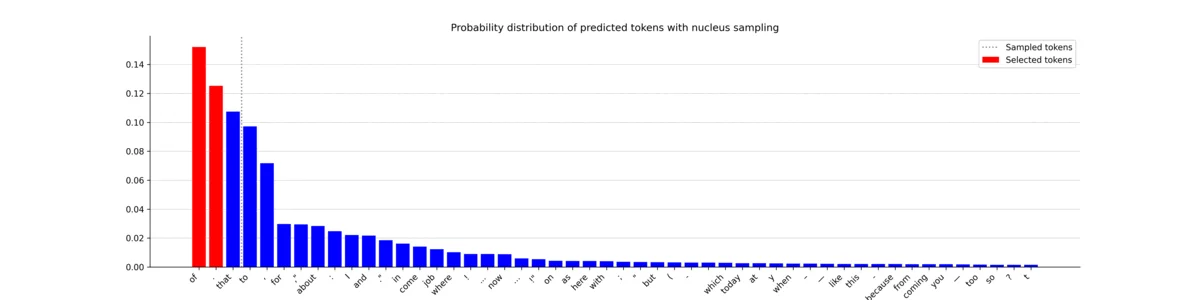
Top-p distribution
The number of tokens on the nucleus can vary from step to step.
If the generated probability distributions vary considerably, the selection of tokens might not be always among the most probable ones.
Generation of unique and varied sequences.

Top-p
Generated text: I have a dream. I'm going to