24. Distillation and Merging
Encoders vs Decoders
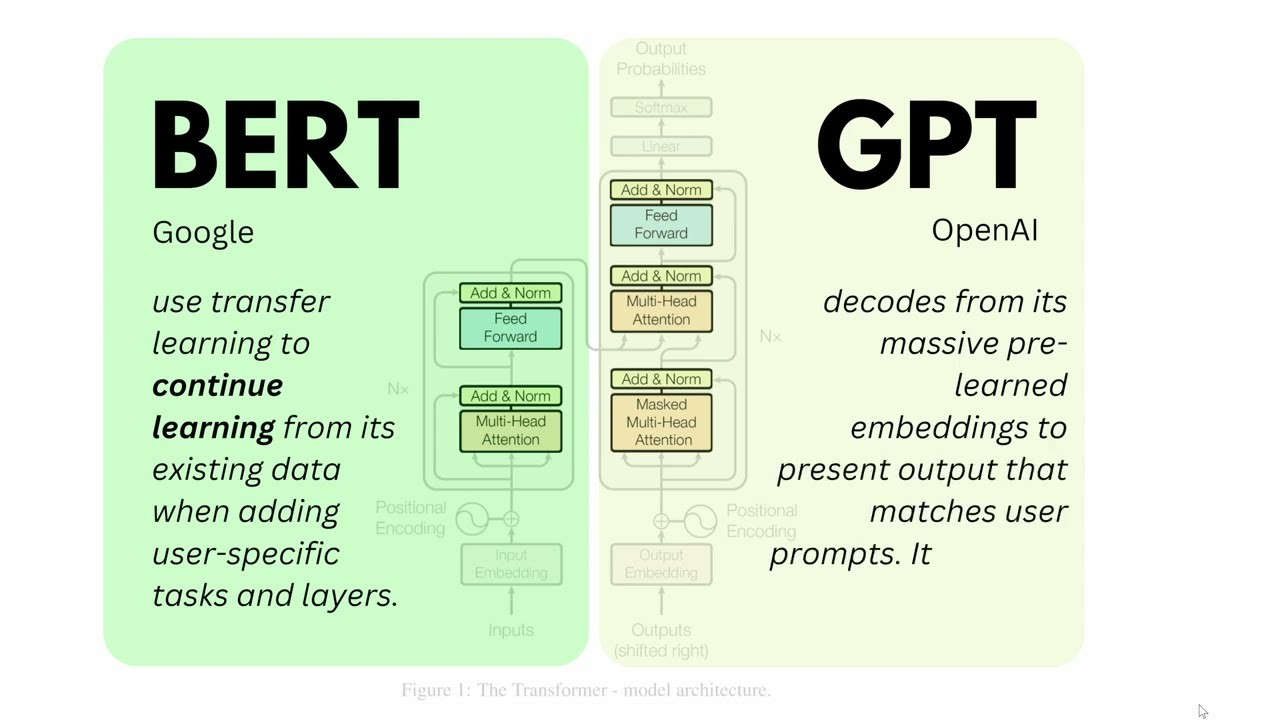
BERT vs GPT
- image source: Ronak Verma
Fine Tuning

distillation motivation
- image source: Google Research
Teacher and Student
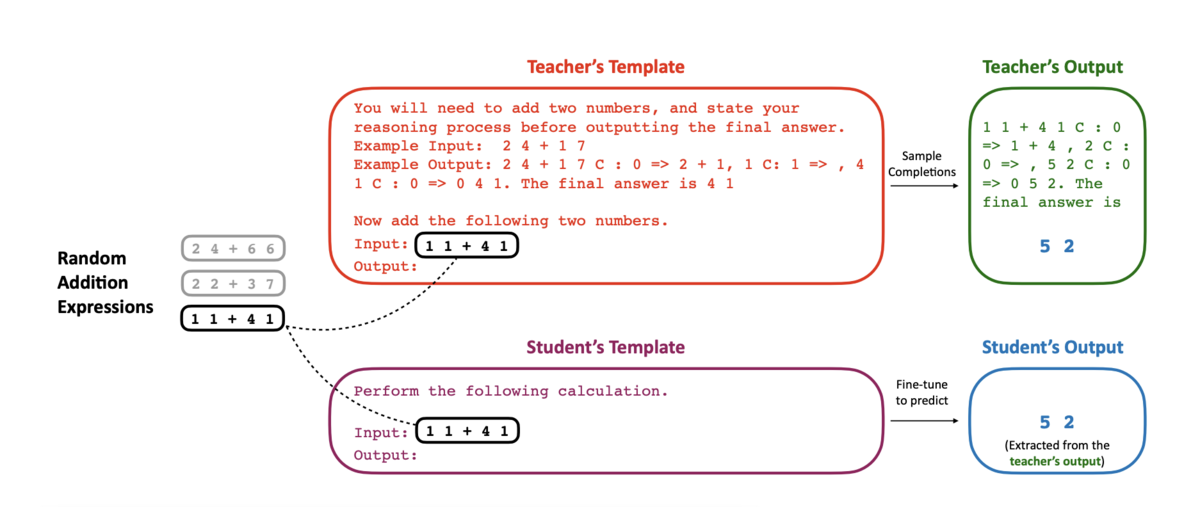
teacher and student
- image source: Snorkel AI
Chain of Thought

chain of thought
- image source: Snorkel AI
DistilBERT Performance
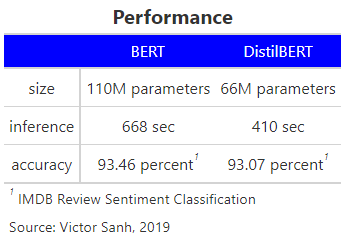
DistilBERT performance