23. Context Scaling
Issues with Long Contexts
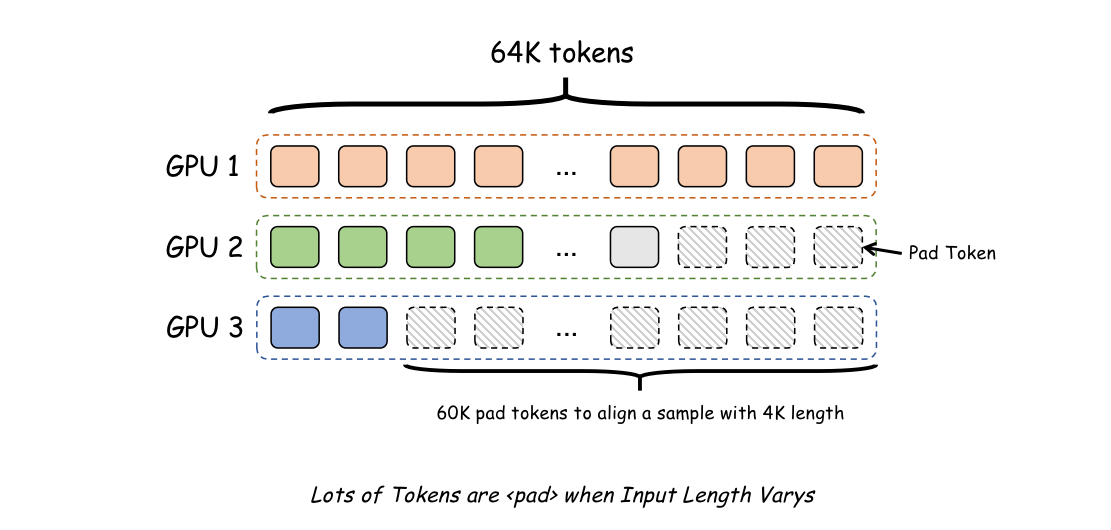
batch alignment
- memory usage
- attention space: \(O(N^{2})\)
RoPE

RoPE matrix
- PE vectors maintain magnitude
- resilient with test data \(>\) training data
- image credit: Eleuther AI
Llama with YaRN
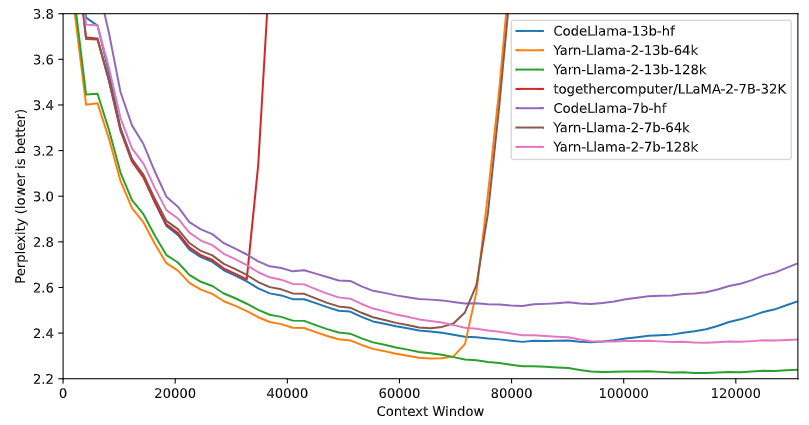
Llama with Yarn
- image credit: Eleuther AI