22. Direct Preference Optimization Methods
Before: RLHF
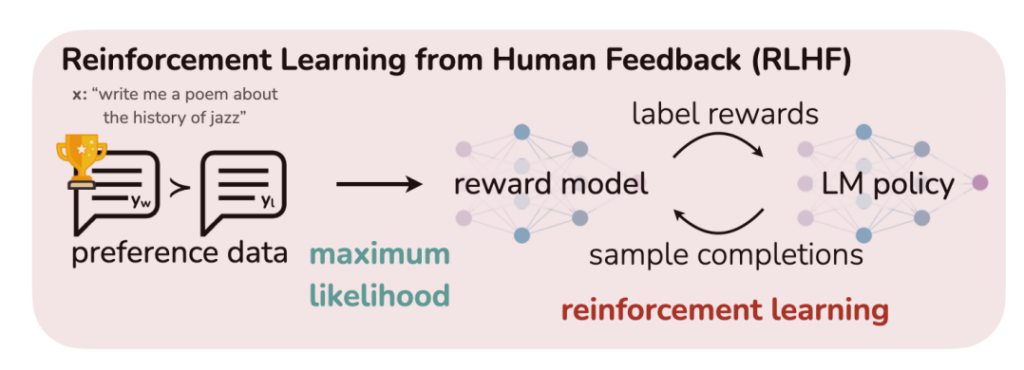
RLHF
- image source: Rafailov et al, 2024
Now: DPO
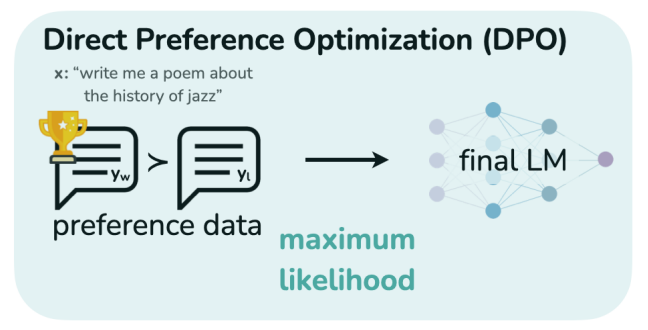
DPO
- “DPO removes the need for the rewards model all together!” — Matthew Gunton
- image source: Rafailov et al, 2024
Policy Iteration
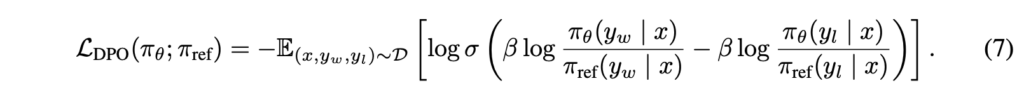
DPO math
- \(y_{w}\) increases
- policies improve
- image source: Rafailov et al, 2024
Motivations
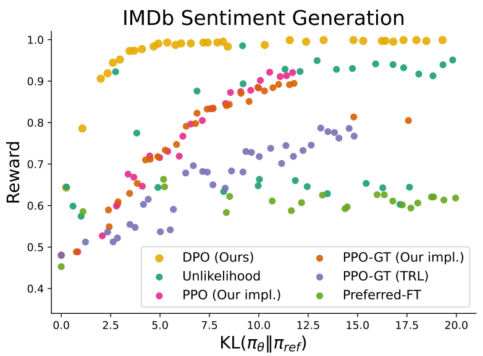
DPO on IMDb data set
- quality data: no need for reward model
- dynamic: update with new data
- precise: can avoid certain topics
- image source: Rafailov et al, 2024
Newer Designs
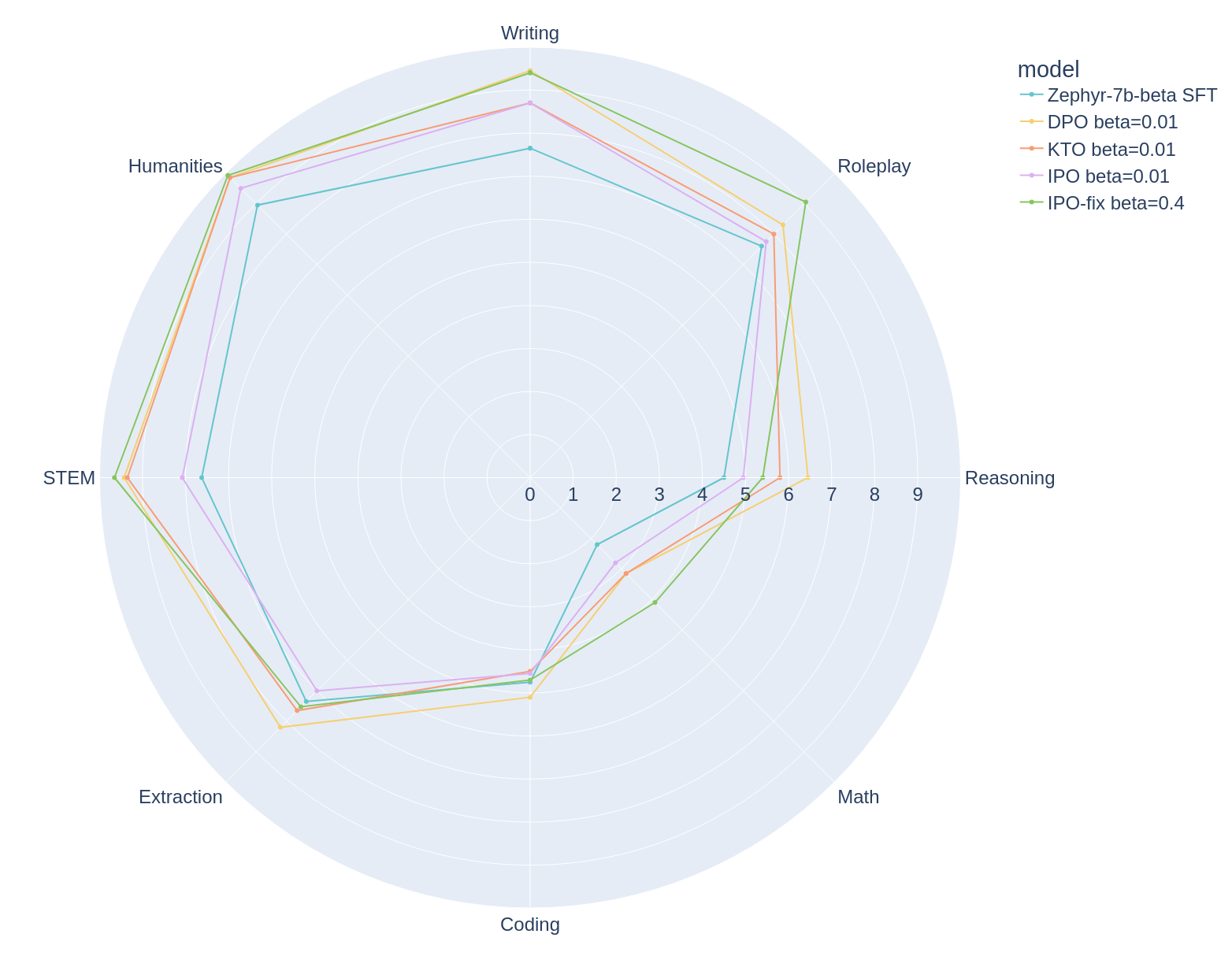
Zephyr models
- image source: Hugging Face