21. Reward Models and RLHF
Continued Pre-Training
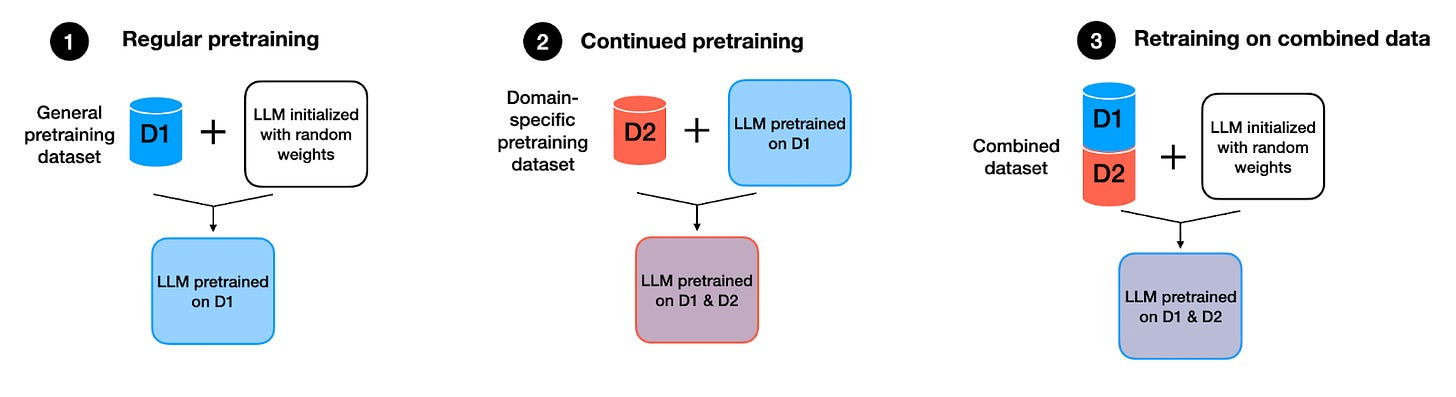
continued pre-training
- image source: Sebastian Raschka
RL
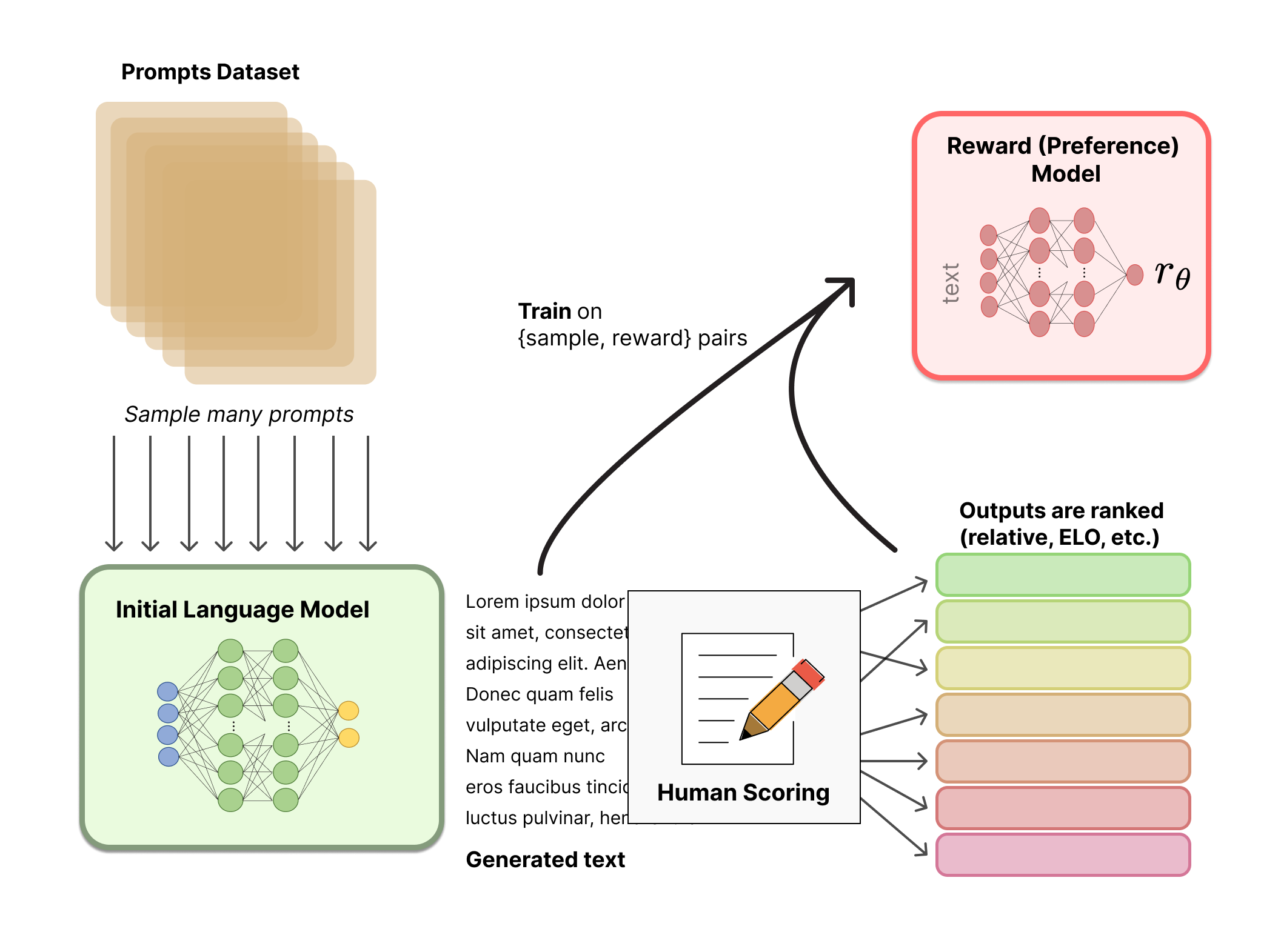
reinforcement learning
- image source: Hugging Face
Preference Classification
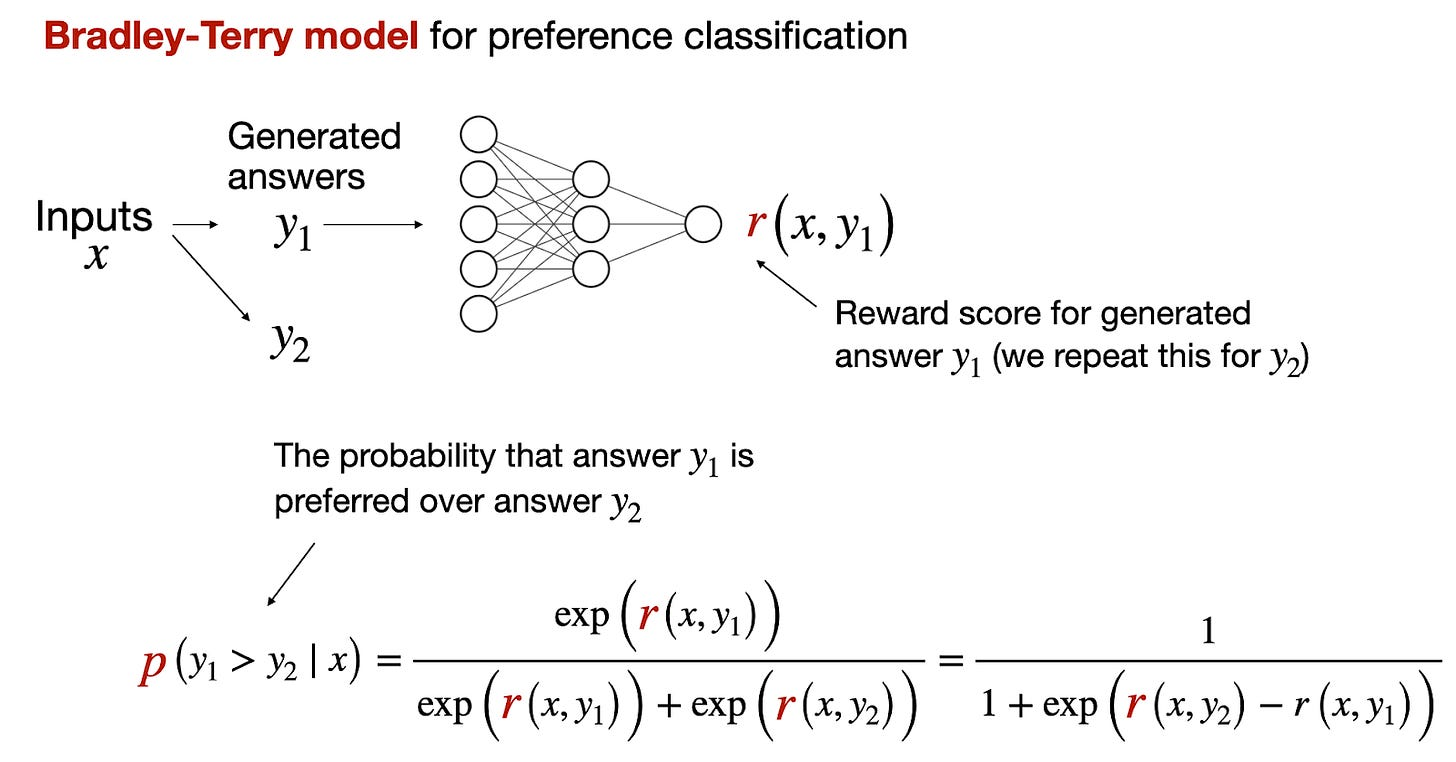
preference classification
- image source: Sebastian Raschka
RLHF

RLHF workflow
- image source: Hugging Face
Toward DPO

toward DPO
- image source: Sebastian Raschka
Human Feedback (moderation)
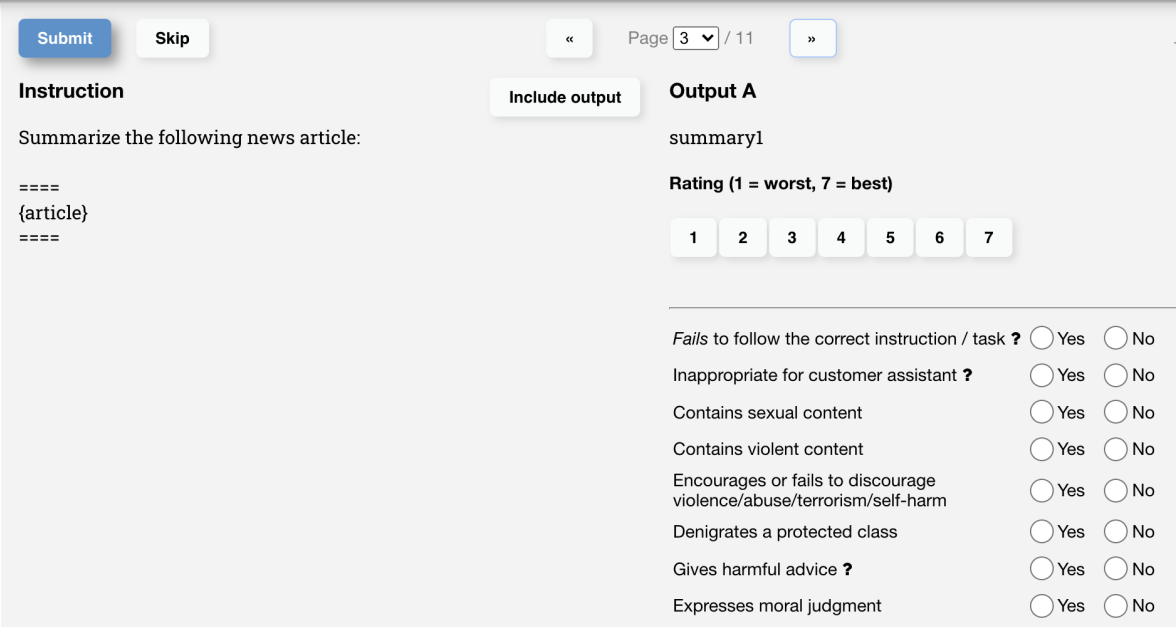
human feedback for moderation
- image source: Chip Huyen by Chip Huyen (author)
Quality of Model Outputs
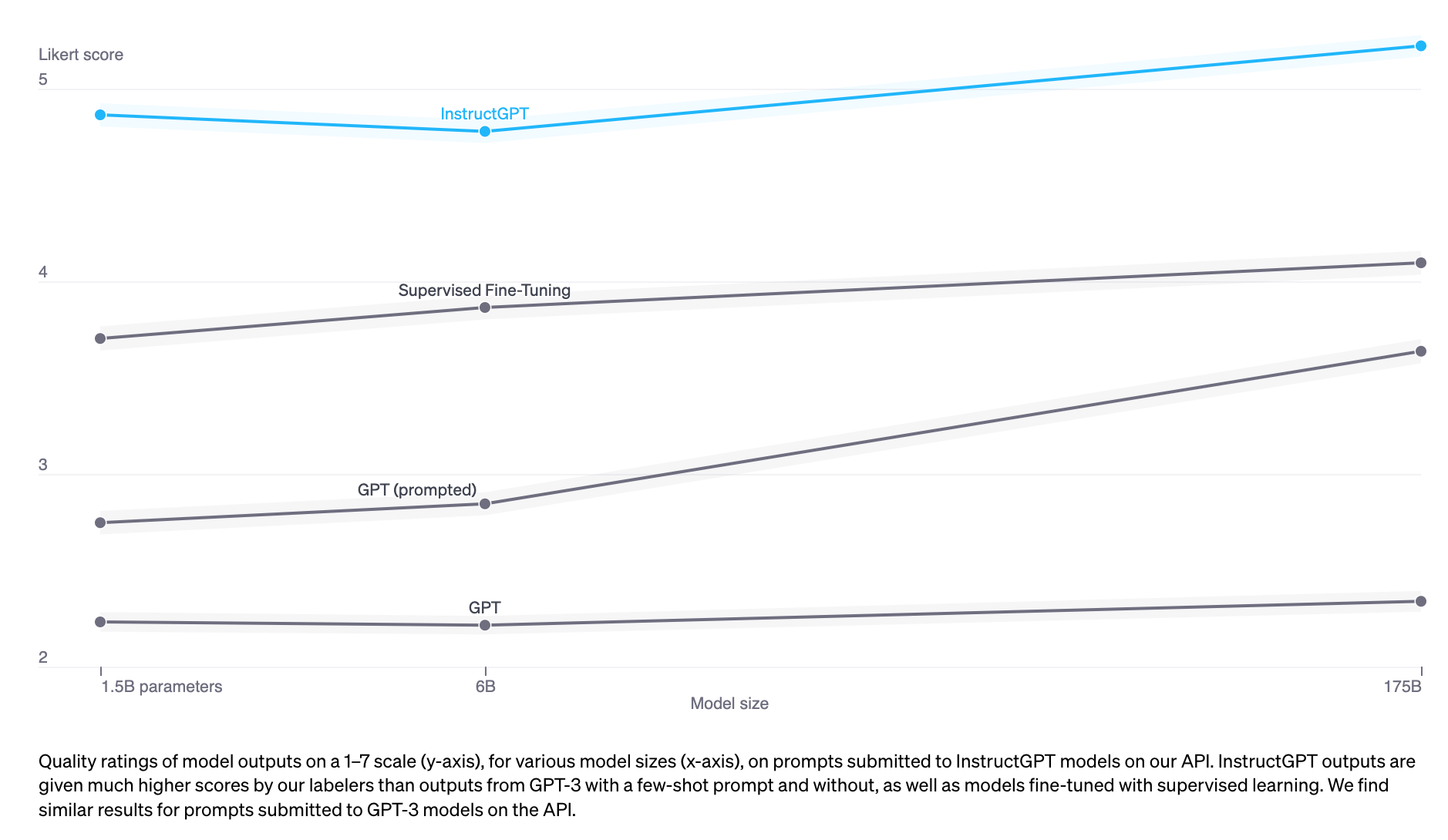
Bai et al., 2022
Selling Points
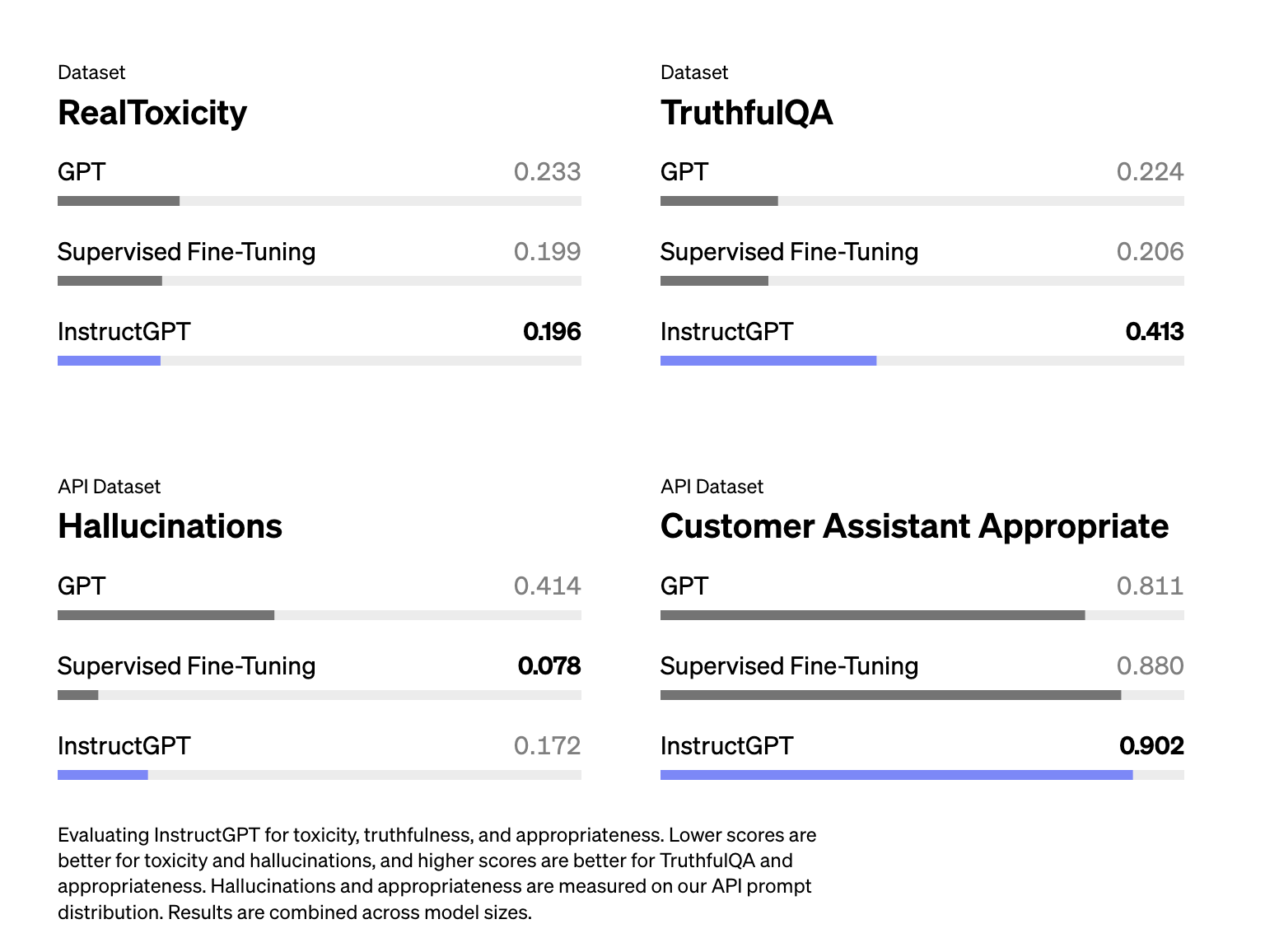
Schulman, 2023