20. Low-Rank Adapters (LoRA)
Palmer Penguins
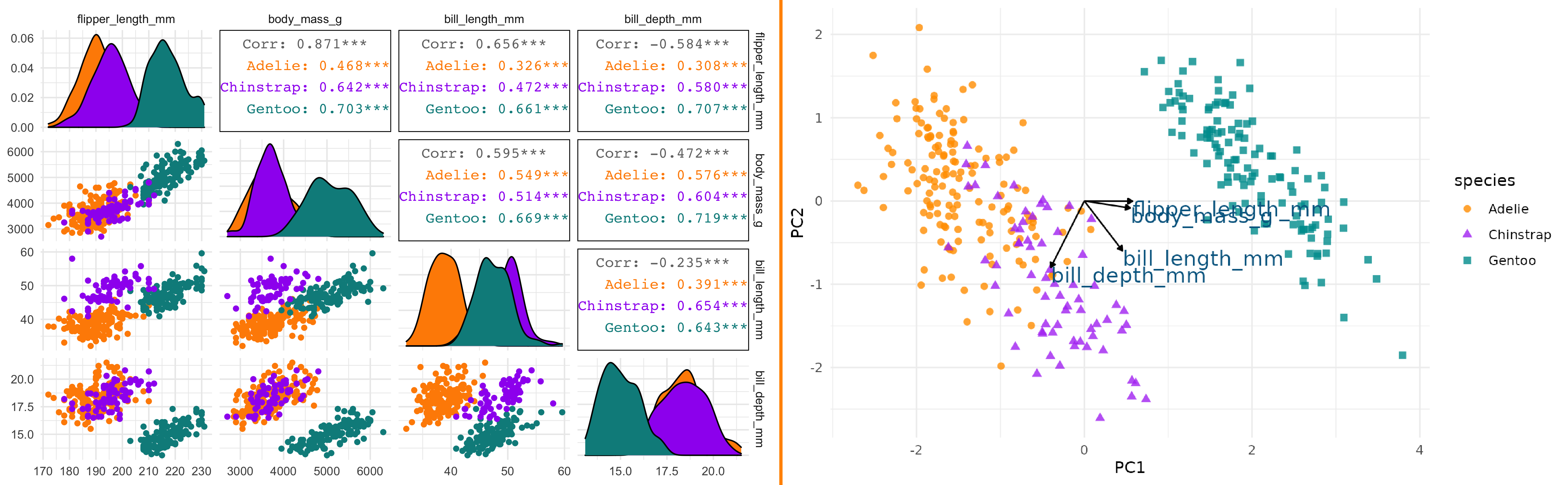
Allison Horst
SVD
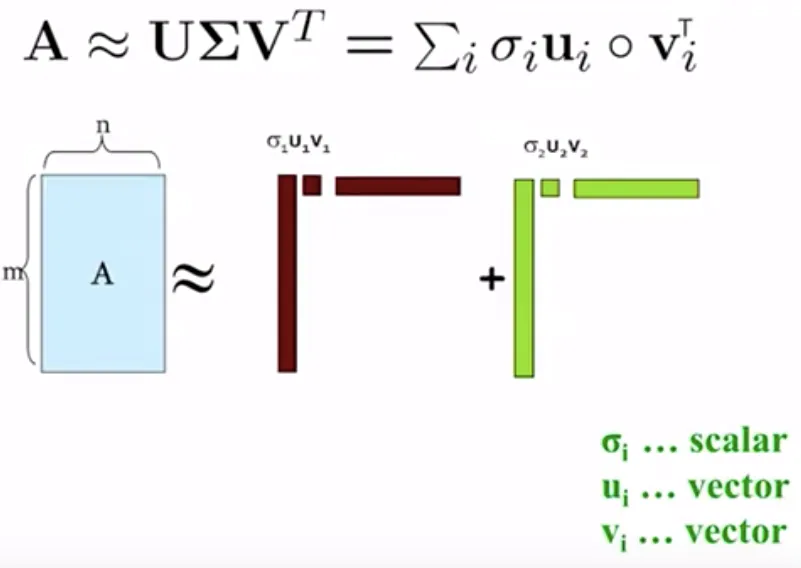
SVD
- image source: Antriksh Singh
Fine Tuning
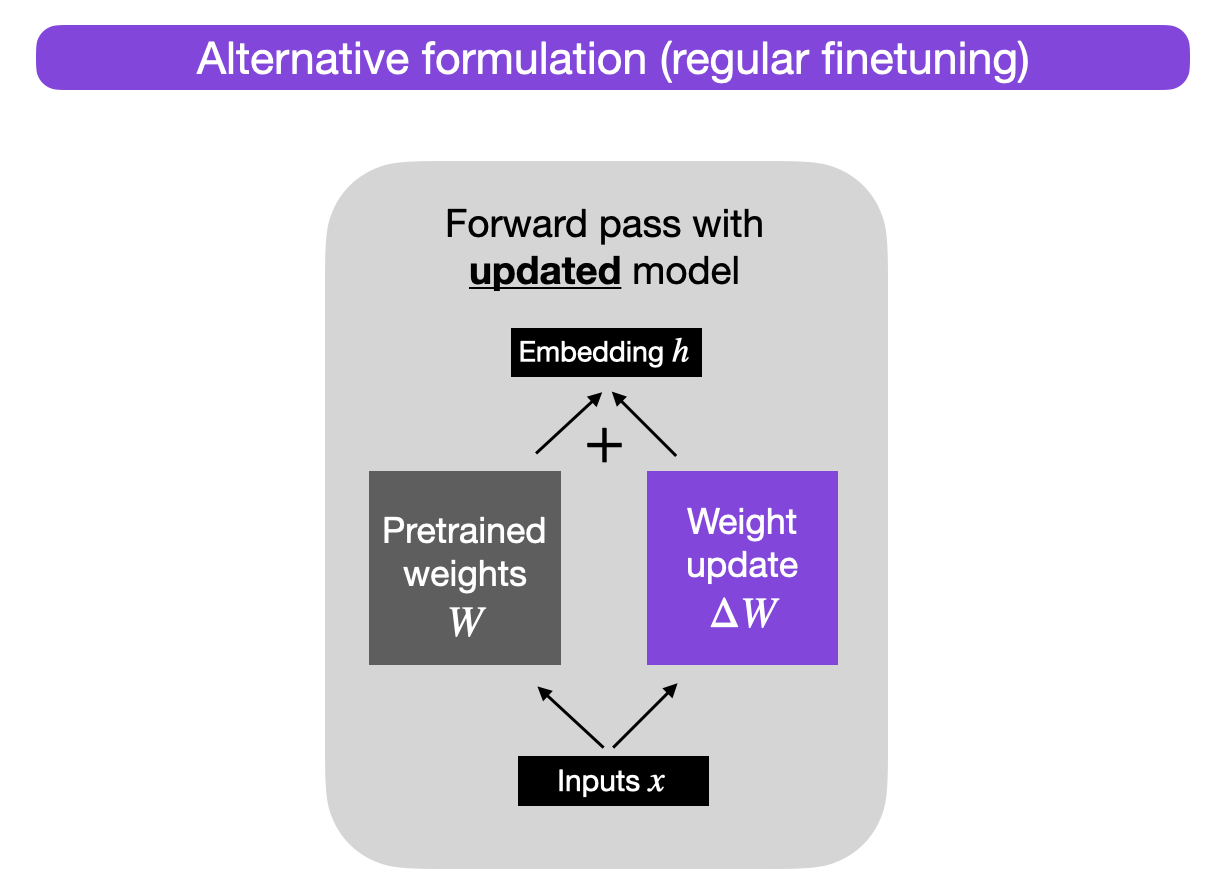
fine tuning scheme
- image source: Sebastian Raschka
Dimensionality Reduction
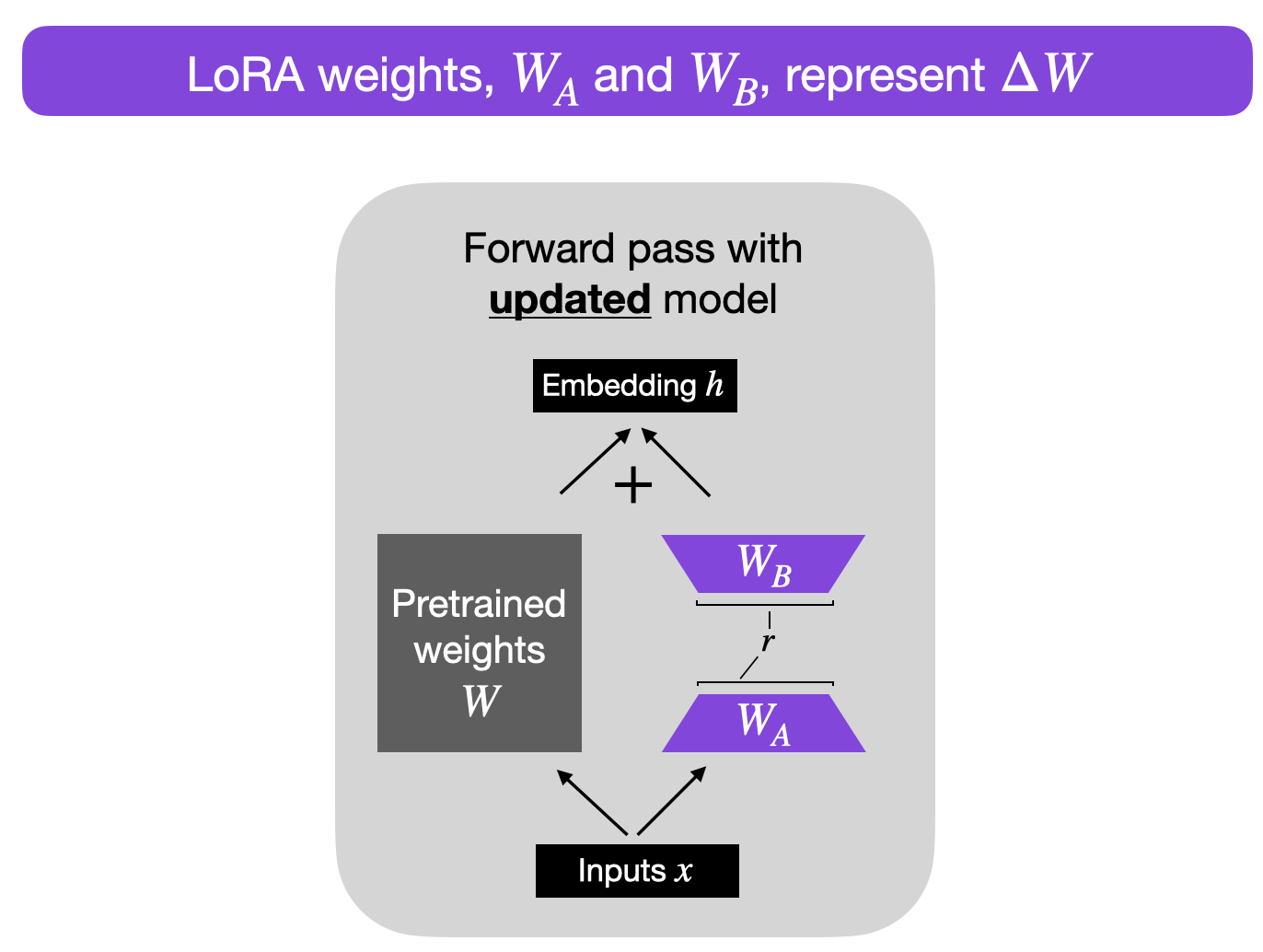
matrix factorization
- image source: Sebastian Raschka
DoRA from Vectors
Weight-Decomposed Low-Rank Adaptation
- \(m\): magnitude vector
- \(V\): directional matrix
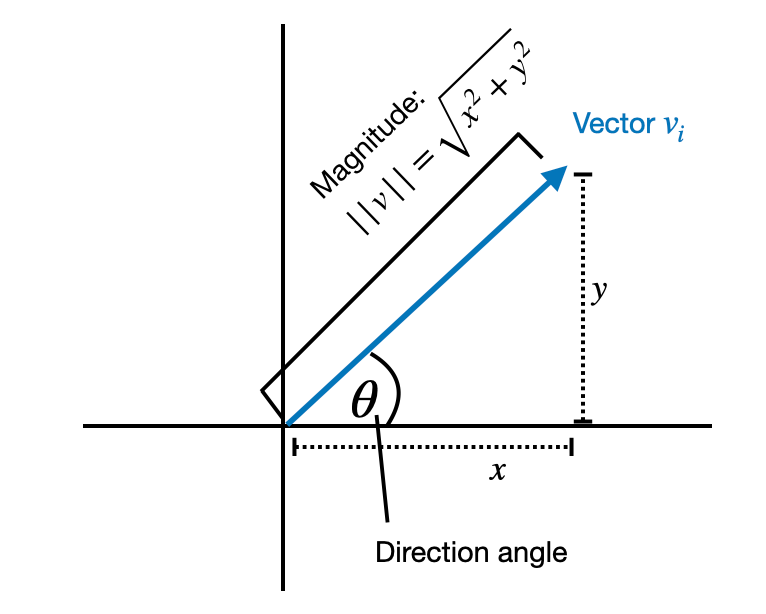
vectors!
DoRA Decomposition
\[W' = m \cdot \frac{W_{0} + BA}{||W_{0} + BA||_{c}}\]
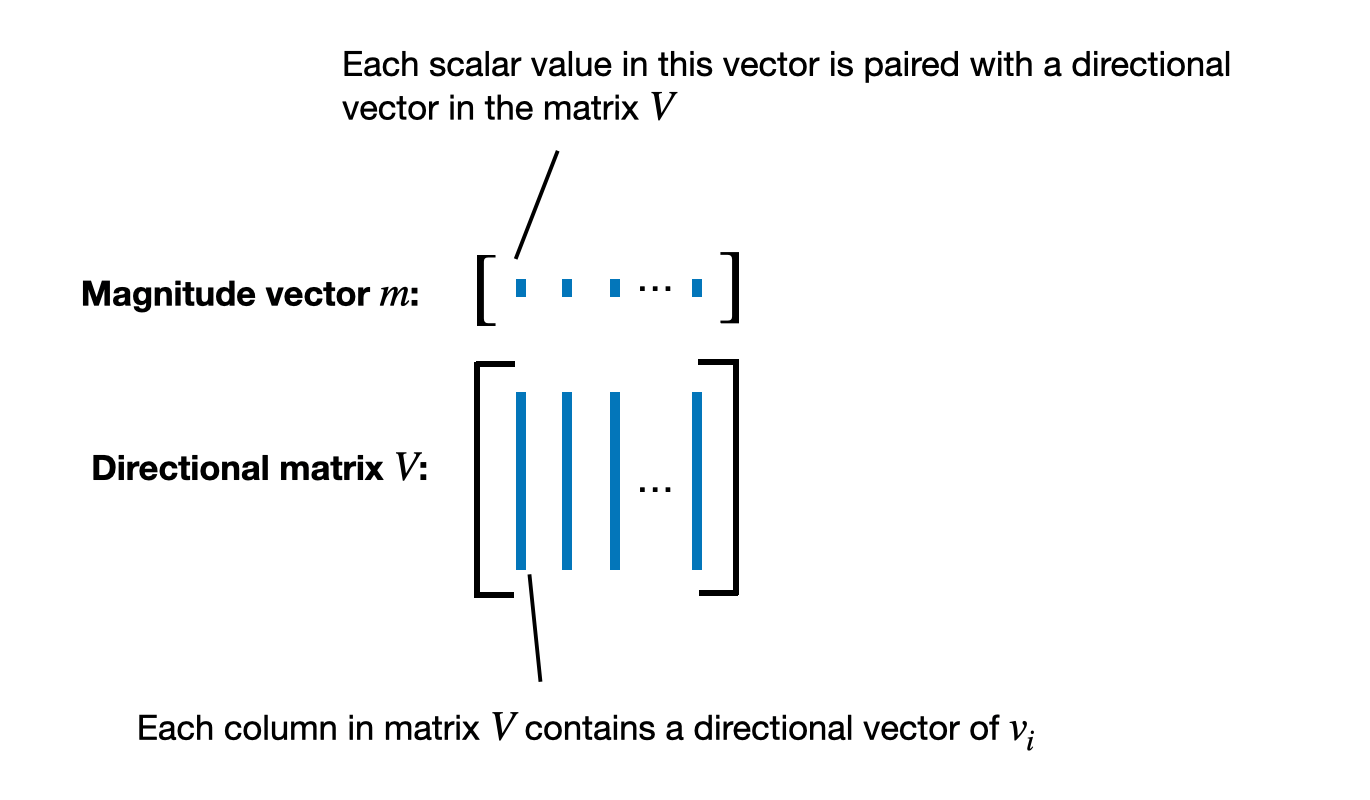
DoRA decomposition
DoRA Workflow
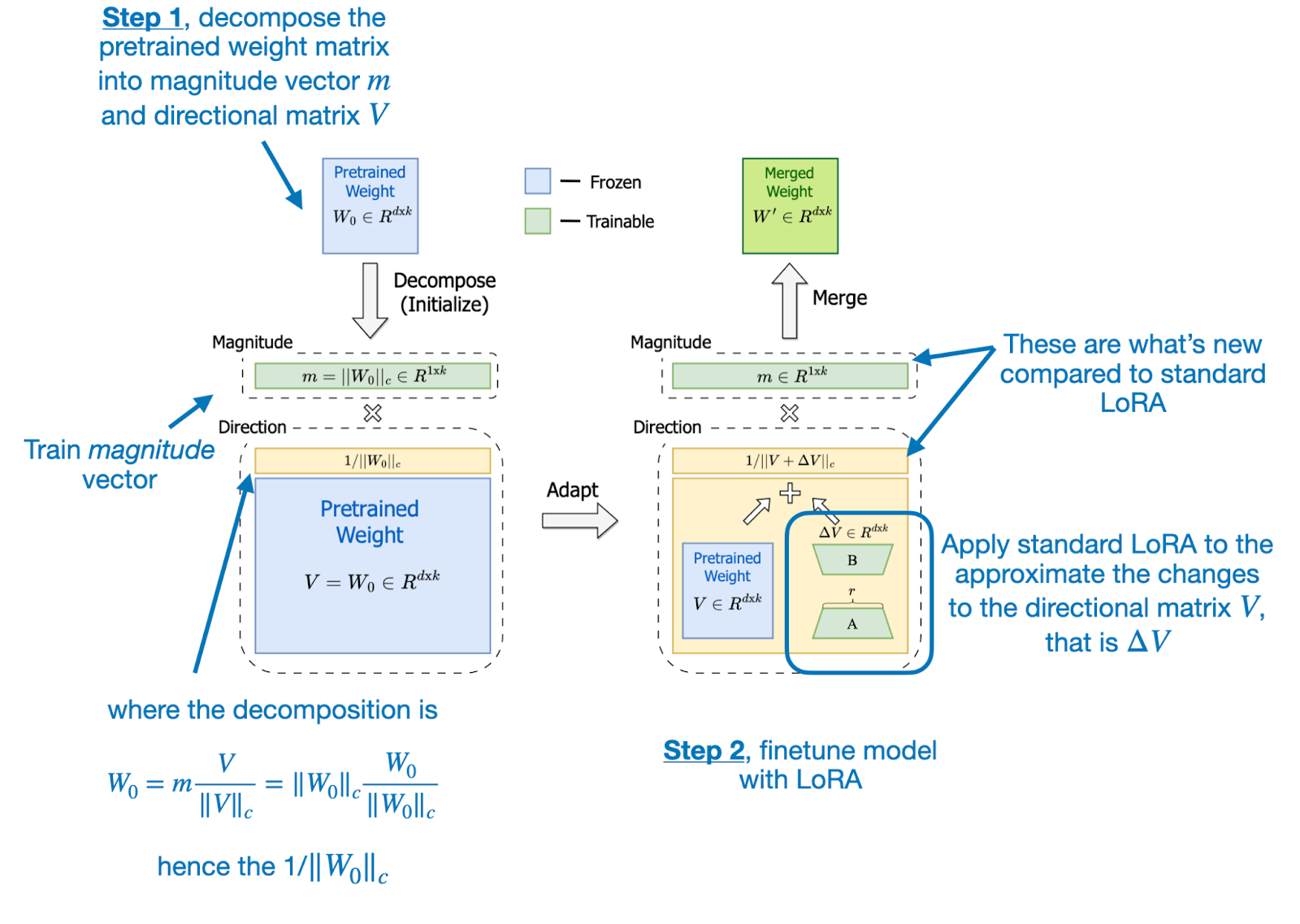
DoRA workflow
- images source: Sebastian Raschka