18. Mixture-of-Experts
Bryan Tegomoh
2025-04-13
Mixture-of-Experts: The Basics
- Chapter 18 from GenAI Handbook
- Goal: Learn MoE for efficient LLMs
- Key idea: Use only some parameters per task
- Builds on: Scaling laws, pretraining
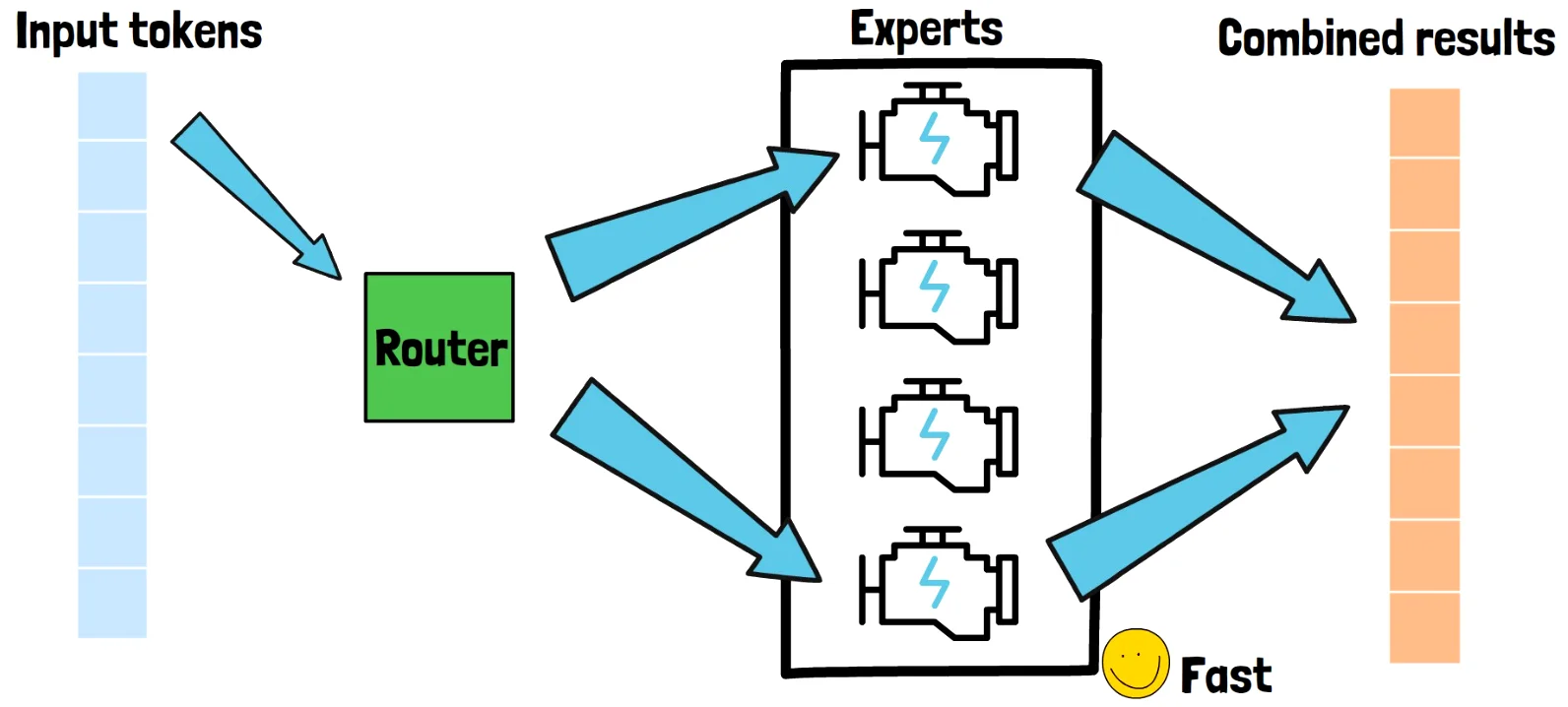
How MoE Works
- Unlike dense models (e.g., Llama3), MoE is sparse
- Experts: Specialized sub-networks per layer
- Router: Picks a few experts per input
- Result: Big model, less compute
Mixture of Experts
Why It Matters
- Efficiency: Less memory/time than dense models
- Scale: Grow “knowledge” without slowing down
- Examples: Mixtral (8x7B, 8x22B), maybe GPT-4