Section III: Foundations for Modern Language Modeling
Focus:
Chapter 15: Pretraining Recipes
Goal: Understand the choices in pretraining LLMs
Builds on: Transformers, Tokenization, Positional encoding
Chapter 16: Distributed Training and FSDP
Goal: Learn how to scale LLM training
Primary Objective: Understand key concepts for training modern LLMs
Why Distributed Training?
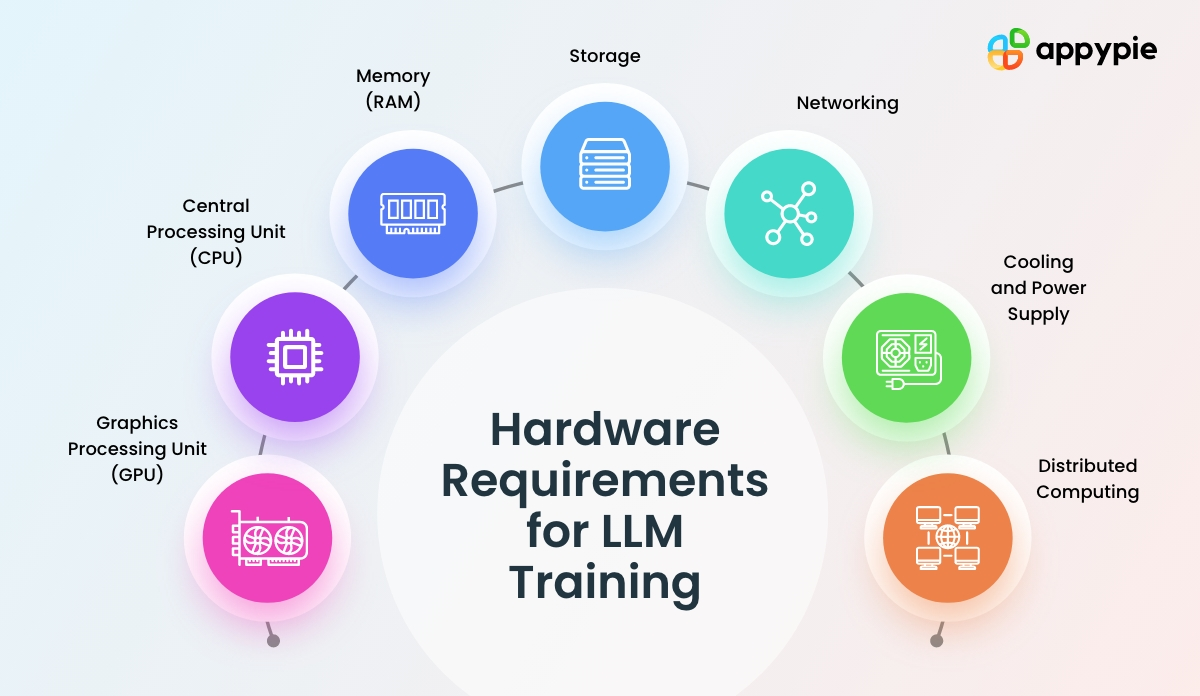
The Scale Challenge: - Modern LLMs: 7B to 1T+ parameters - Single GPU memory (A100): Only 40-80GB - 7B model memory requirements: - Weights: ~14GB (FP16) - Gradients: ~14GB - Optimizer states: ~28GB (Adam) - Activations: Variable with batch size
Solution: Split computation across multiple devices
Hardware Requirements for LLM Training
GPU Memory Requirements
Parallelism Strategies
Four primary approaches:
Data Parallelism:
Same model, different data batches
Simple but limited by model size
Model Parallelism:
Different layers on different devices
Enables larger models but sequential processing
Pipeline Parallelism:
Stages of model on different devices
Multiple batches in pipeline
Tensor Parallelism:
Split individual operations (matrices)
Efficient for Transformer operations
Improving Optimization Performance with Parallelism Computing
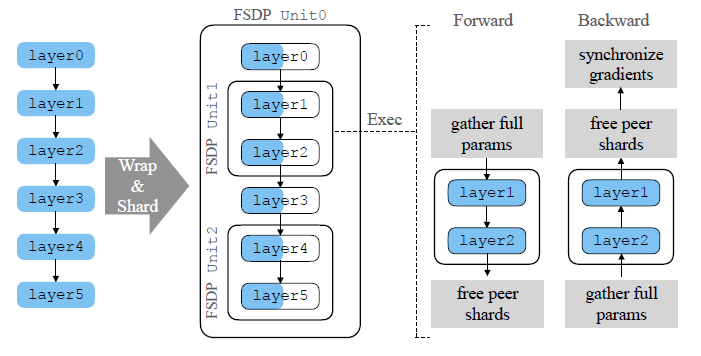
Full Sharded Data Parallelism (FSDP)
Core Concept: Shard model parameters, gradients, and optimizer states
How it works: - Each device stores only a portion of the full model - During forward/backward pass: - Gather needed parameters (all-gather) - Compute with gathered parameters - Re-shard parameters after use
Benefits: - ~N-fold memory reduction with N devices - Enables training much larger models - Preserves computation efficiency of data parallelism
Full Sharded Data Parallelism (FSDP)
Critical Memory Optimizations
Combine these techniques for maximum efficiency:
Mixed Precision Training:
Use BF16/FP16 for most operations
Maintain FP32 master weights for stability
2x memory reduction
Activation Checkpointing:
Discard activations during forward pass
Recompute during backward pass
Trade computation for memory
Gradient Accumulation:
Update less frequently
Process more data with same memory
FSDP Implementation (PyTorch)
Basic implementation:
# Initialize distributed process grouptorch.distributed.init_process_group("nccl")# Wrap model with FSDPmodel = FSDP( model, sharding_strategy=ShardingStrategy.FULL_SHARD, mixed_precision=mp_policy, device_id=torch.cuda.current_device())# Train normallyfor batch in dataloader: loss = model(batch).loss loss.backward() optimizer.step()
Communication Bottlenecks: - All-gather: Collect sharded parameters - Reduce-scatter: Aggregate gradients - Communication volume grows with model size
Optimization Strategies: - Match parallelism strategy to hardware topology - Hierarchical communication patterns - Overlap computation with communication
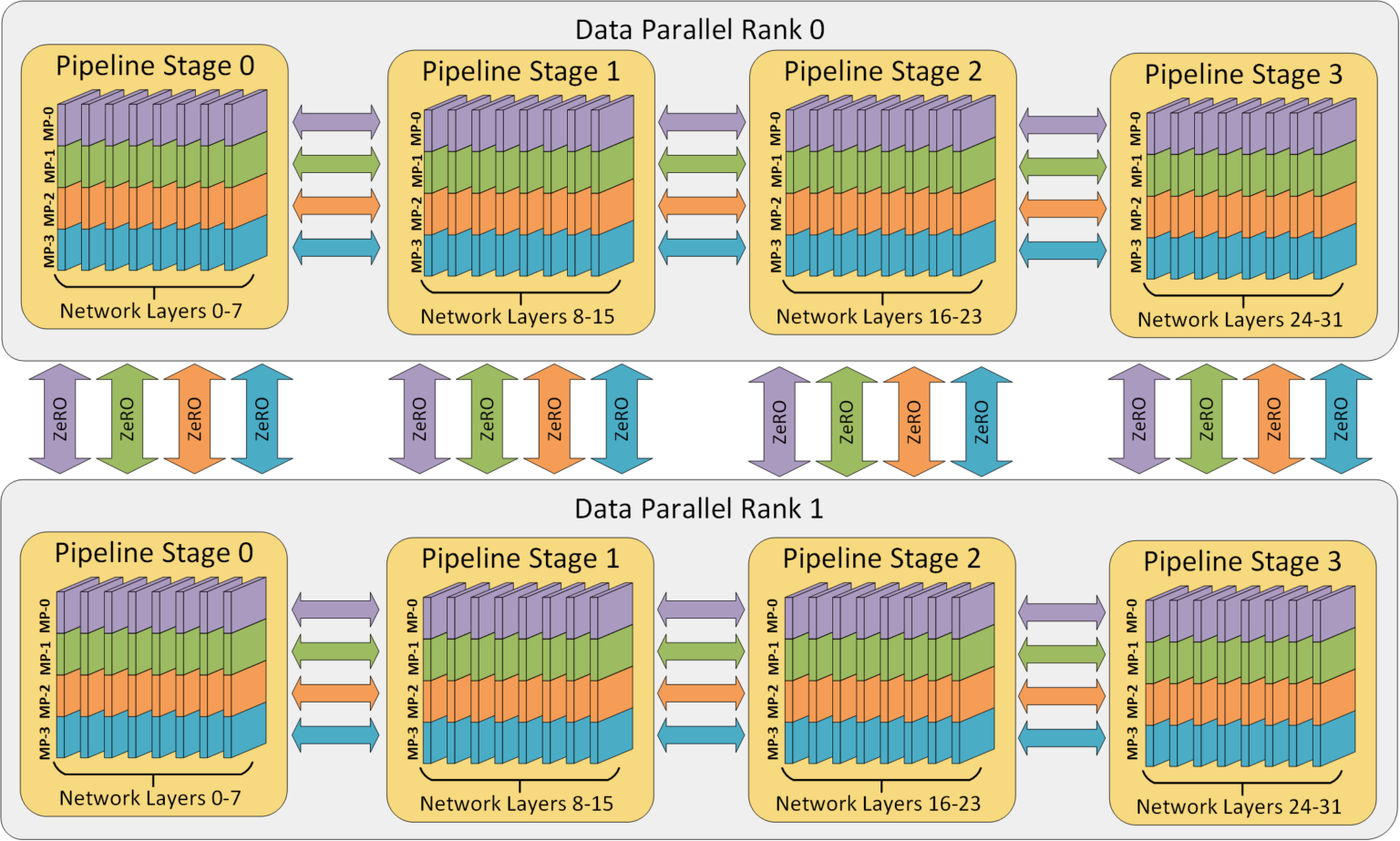
3D Parallelism: State-of-the-Art
Combining complementary strategies:
Data Parallelism/FSDP: Across node groups
Pipeline Parallelism: Between GPU clusters
Tensor Parallelism: Within GPU clusters
Example (175B model training): - 8-way tensor parallelism - 12-way pipeline parallelism - 32-way data parallelism - Total: 3,072 GPUs