14. Positional Encoding
2025-03-30
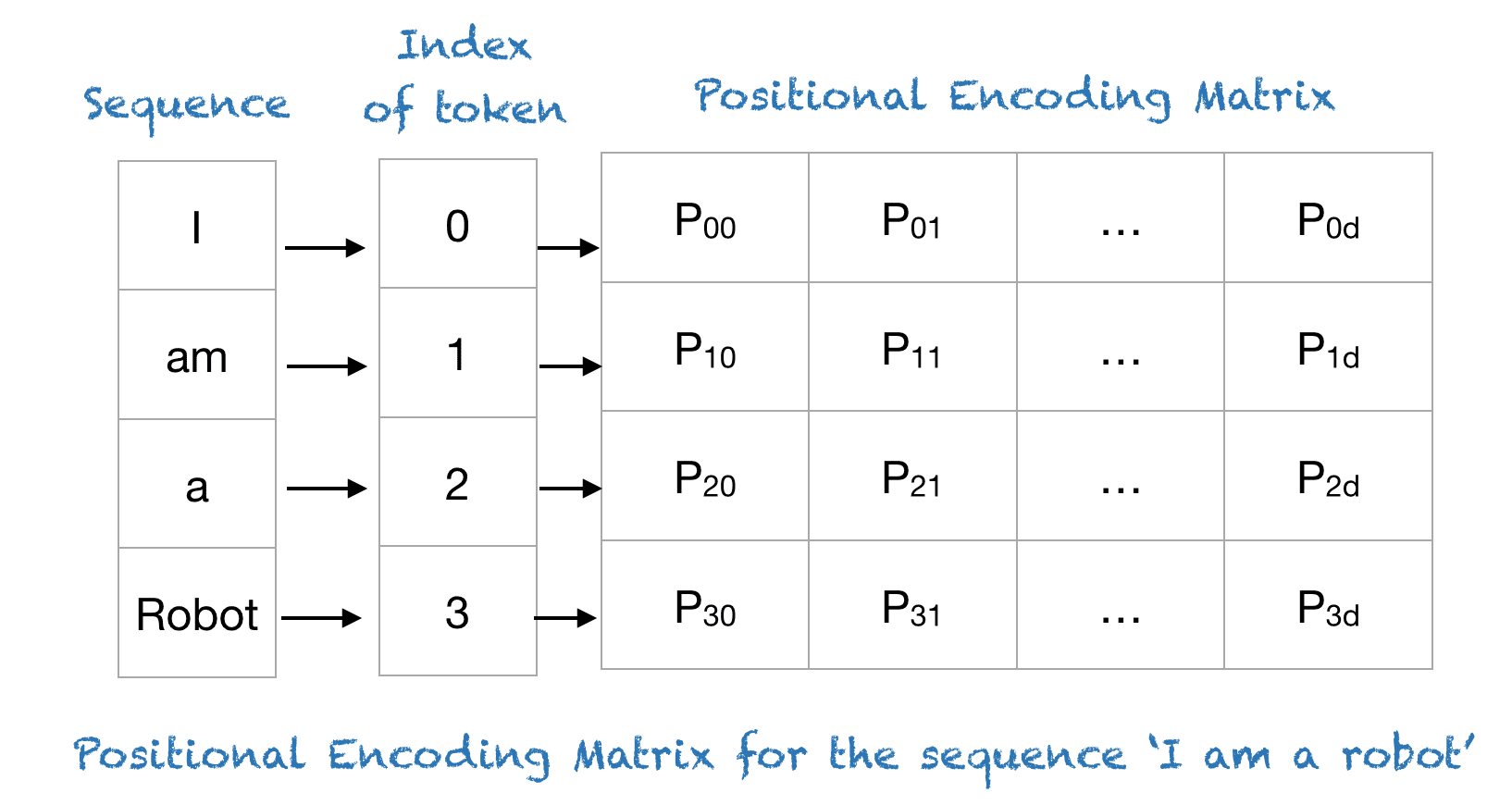
Why Positional Encoding?
Transformers lack recurrence (unlike RNNs)
No inherent sense of word order
Solution: Add positional info to token embeddings
![]()
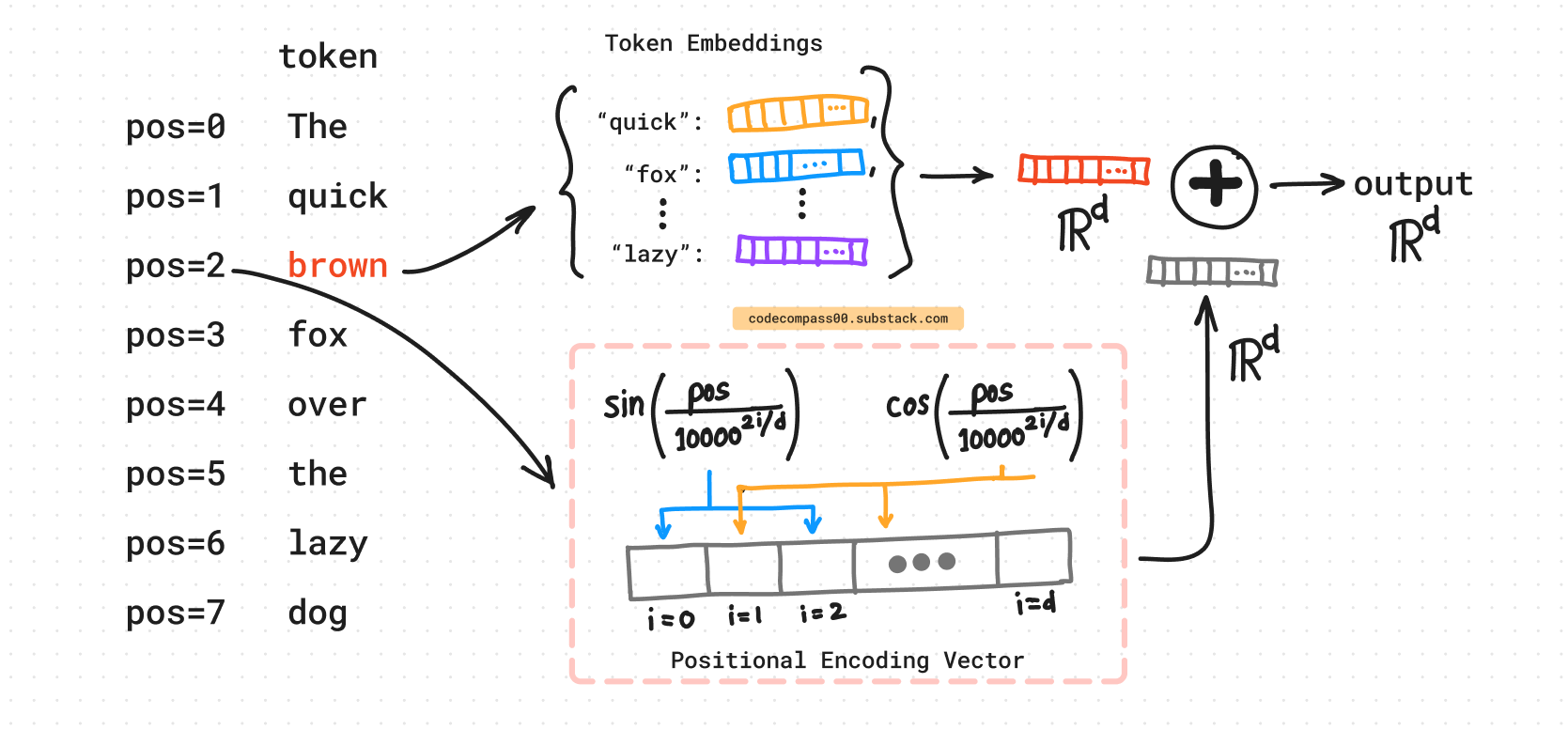
The Power of Positional Encoding
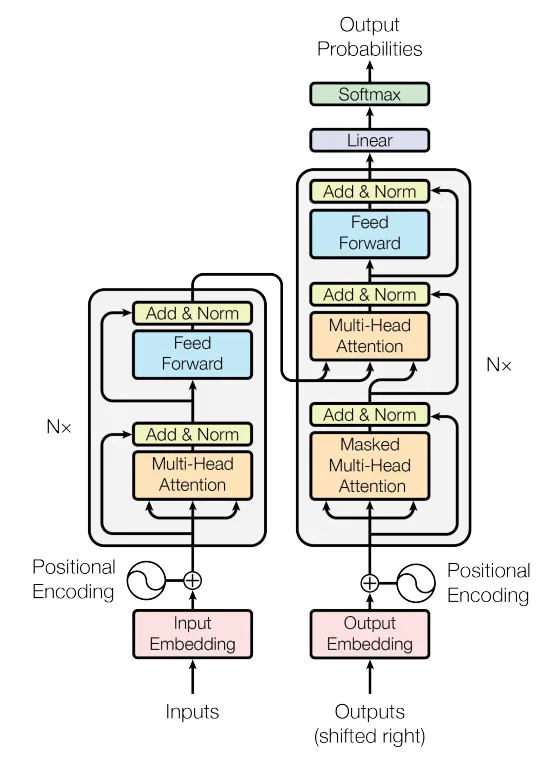
Transformer Architecture
2025-03-30
Transformers lack recurrence (unlike RNNs)
No inherent sense of word order
Solution: Add positional info to token embeddings