13. Tokenization
2025-03-30
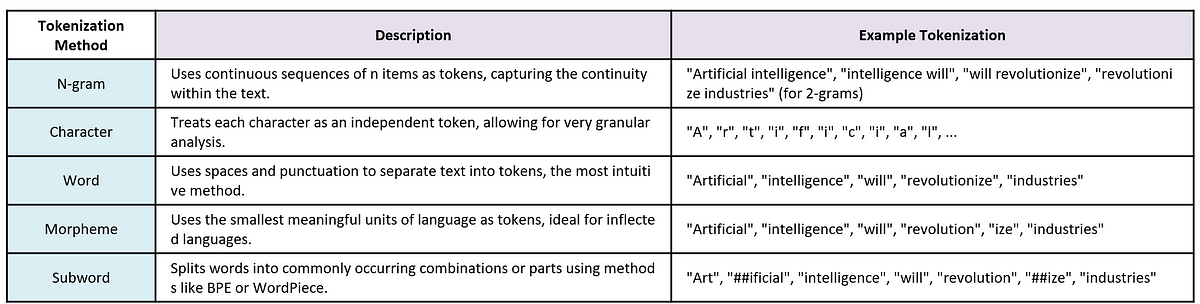
What is Tokenization?
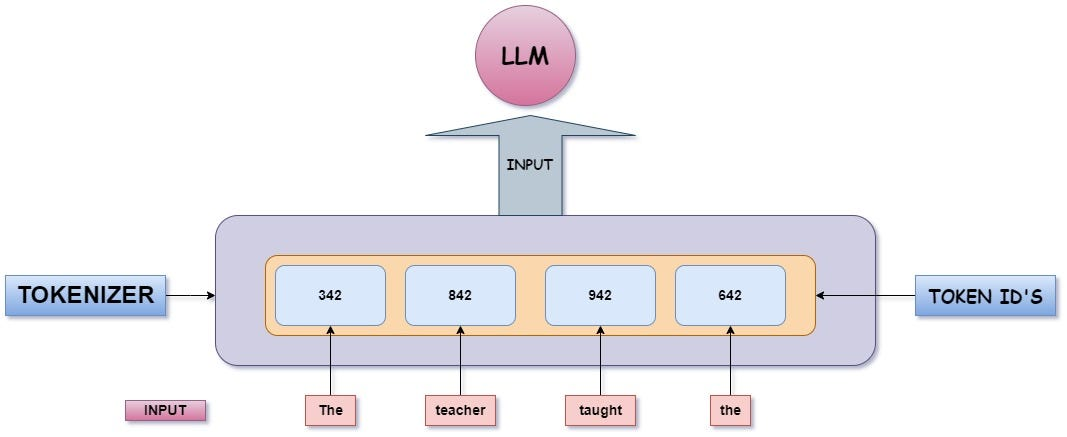
- Converting text into manageable units (tokens) for LLMs
- Why it’s critical:
- LLMs process tokens, not raw characters or full words
- Impacts efficiency and generalization
![]()
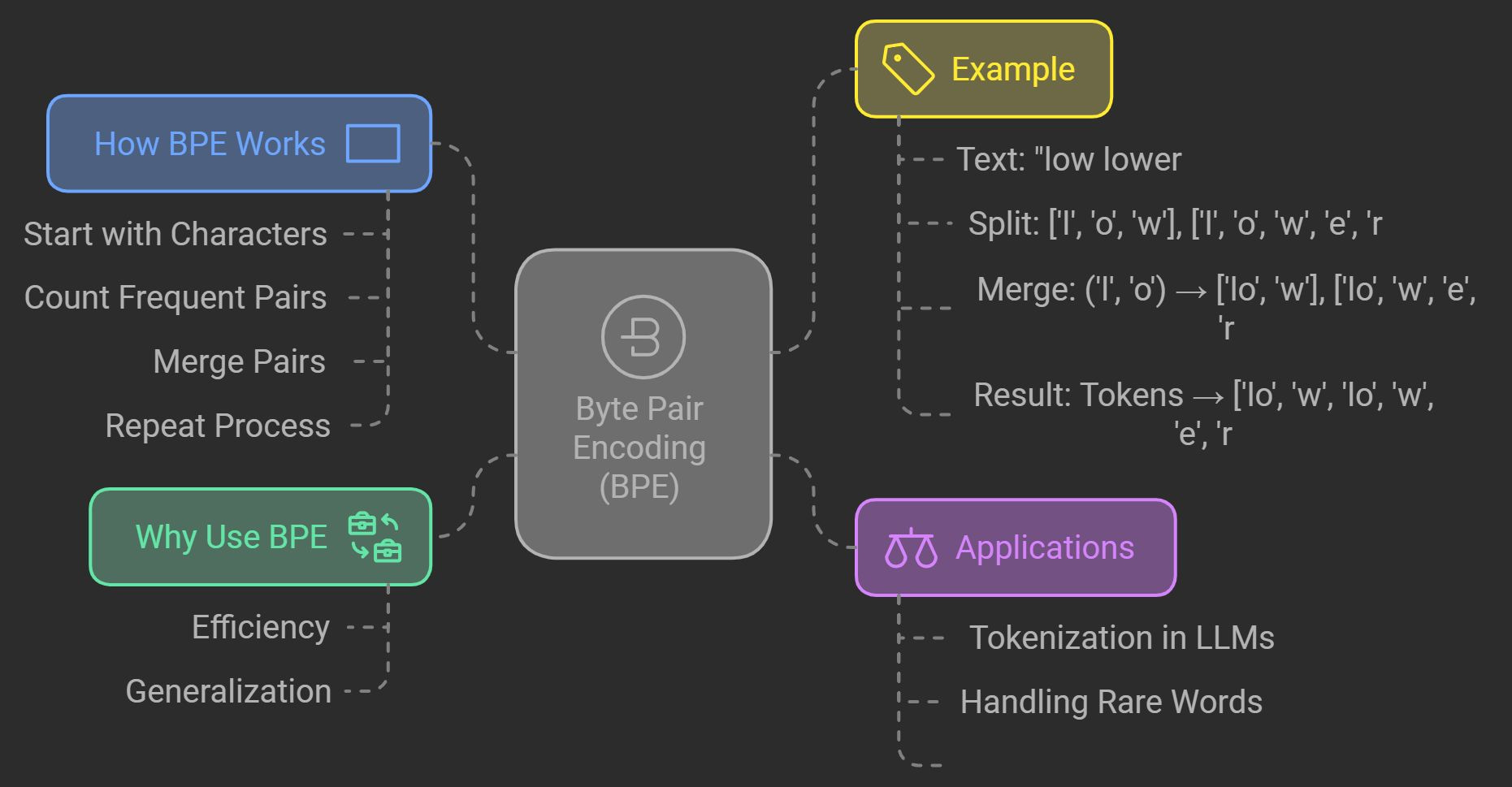
Tokenization Approaches
- Character-level: Each char = token
- Pros: Simple, handles all inputs
- Cons: Inefficient (long sequences)
- Word-level: Each word = token
Pros: Intuitive, shorter sequences
Cons: Fixed vocab → unseen words/misspellings
![]()