11. Encoders and Decoders
Bidirectional Recurrent Neural Networks
Background : Unidirectional recurrent neural networks can take in a variable-length sequence and predict an output.
“I am ___.”
Problem : Sometimes it may be necessary __ to take in a variable-length sequence, with one element missing, and predict that element.__
“I am ___ hungry.”
“I am ___ hungry, and I can eat half a pig.”
In the first sentence “happy” seems to be a likely candidate. The words “not” and “very” seem plausible in the second sentence, but “not” seems incompatible with the third sentences.
Solution : Use an RNN in each direction. One RNN predicts forwards. The other predicts backwards. The outputs of the 2 RNN’s are concatenated together.
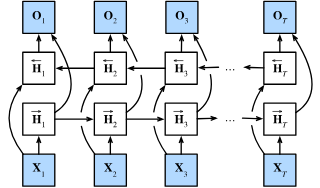
“I am ___ hungry.”
“I am ___ hungry, and I can eat half a pig.”
Solution : Use an RNN in each direction. One RNN predicts forwards. The other predicts backwards. The outputs of the 2 RNN’s are concatenated together.
The Encoder–Decoder Architecture

Sequence Fixed Size __ Sequence__
Can handle inputs and outputs that both consist of variable-length sequences and thus are suitable for sequence-to-sequence problems such as machine translation.
The encoder takes a variable-length sequence as input and transforms it into a state with a fixed shape.
The decoder maps the encoded state of a fixed shape to a variable-length sequence.

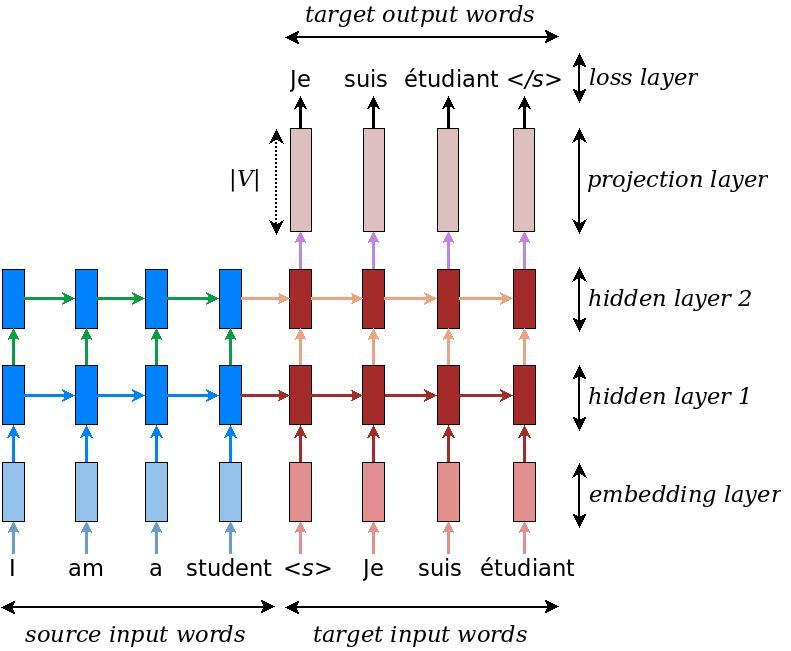
Sequence-to-Sequence Learning for Translation
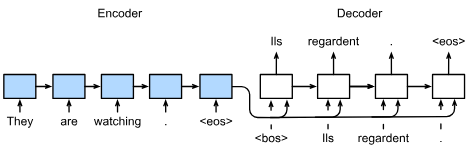
The special “<eos>” token marks the end of the sequence. Our model can stop making predictions once this token is generated. Also “<bos>” is beginning.
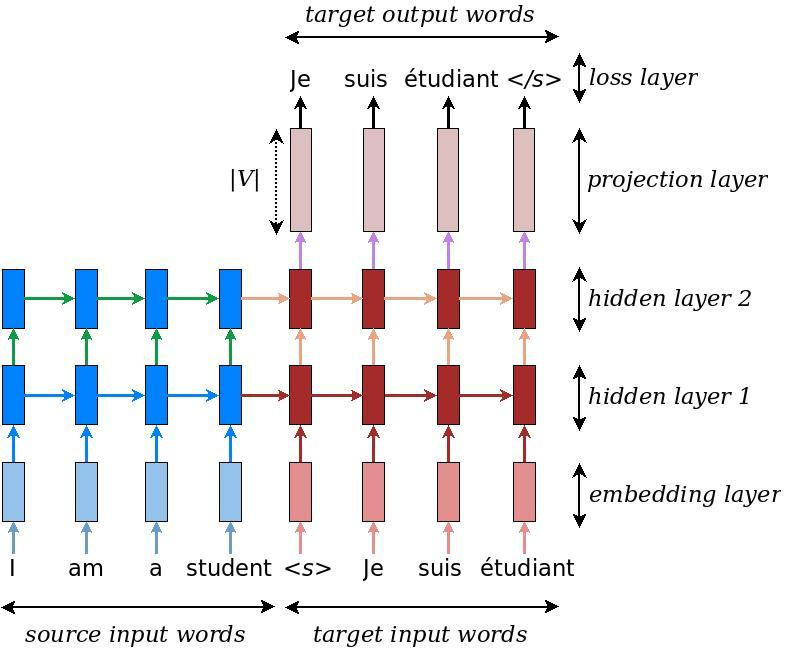
Embedding layer (one-hot encoding to embedding encoder, and embedding to on-hot encoding decoder, not shown)
Teacher forcing can be used in training (decoder uses correct, not predicted, output in LSTM cells). Teacher forcing means, during encoder-decoder LSTM training, instead of using predicted item (word) as input to next LSTM, use correct item (word) as input to next LSTM.
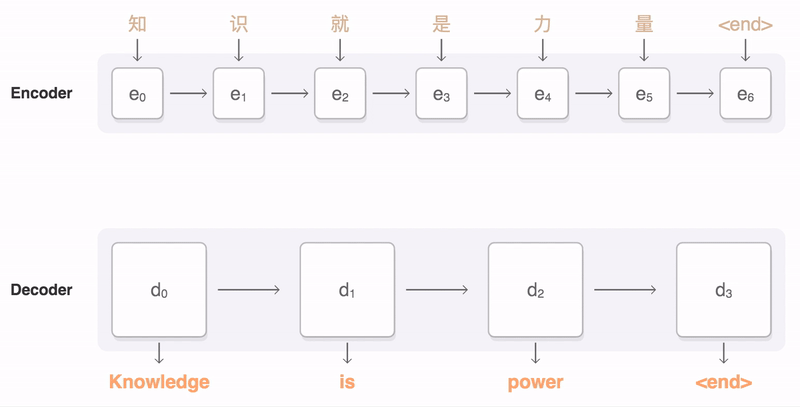
Sequence-to-Sequence (seq2seq) Encoder-Decoder
After receiving __ the <end of sequence> token we stop iterating the decoder.__
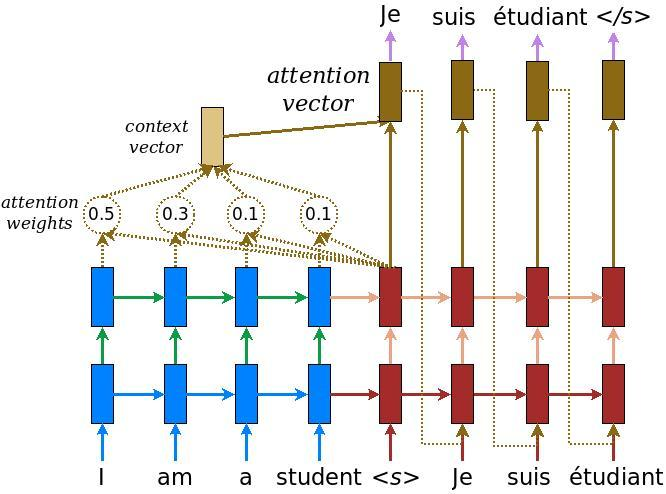
Attention
The key idea of the attention mechanism is to establish direct short-cut connections between the target and the source by paying “attention” to relevant source content as we translate.
When translating each word in the output (decoder) we want to “pay attention” to the most currently relevant word in from the input (encoder).
Seq2Sec Attention
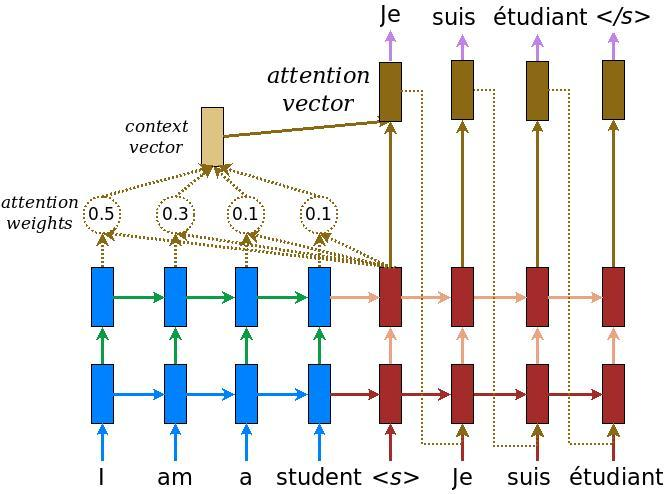
Attention
Decoder can “peek” at previous encoder hidden states (treating them as a dynamic memory of the source information). Improves the translation of longer sentences.
Seq2Sec
Passes the last source state from the encoder to the decoder when starting the decoding process. For long sentences, the single fixed-size hidden state becomes an information bottleneck. Discards all of the hidden states computed in the source RNN

Decoder can “peek” at previous encoder hidden states (treating them as a dynamic memory of the source information). Improves the translation of longer sentences.
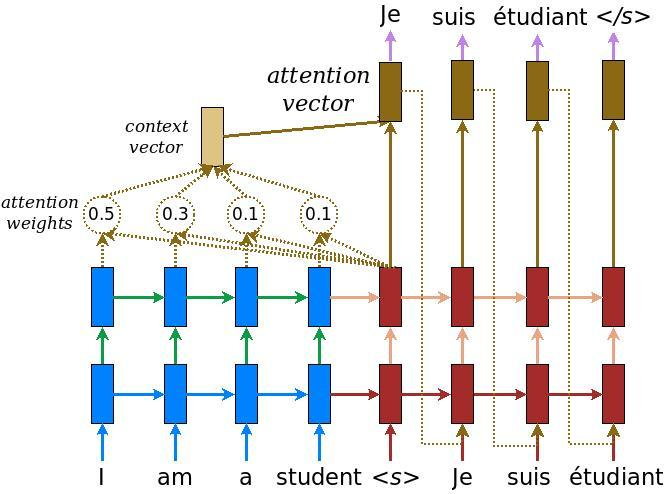
M ethod to determine the relative importance __ of each component in a sequence relative to the other components in that sequence.__
Importance is represented by “soft” weights assigned to each word in a sentence.
Attention encodes a fixed-width context vector __ at each stage a sequence.__
Unlike “hard” weights, which are computed during the backwards training pass, “soft” weights exist only in the forward pass and therefore change with every step of the input.
In the Encoder-Decoder Architecture, the context vector is the weighted sum of the input hidden states and is generated for every time instance in the output sequences.
Context vector is trained using 3 vectors: key, query, and value
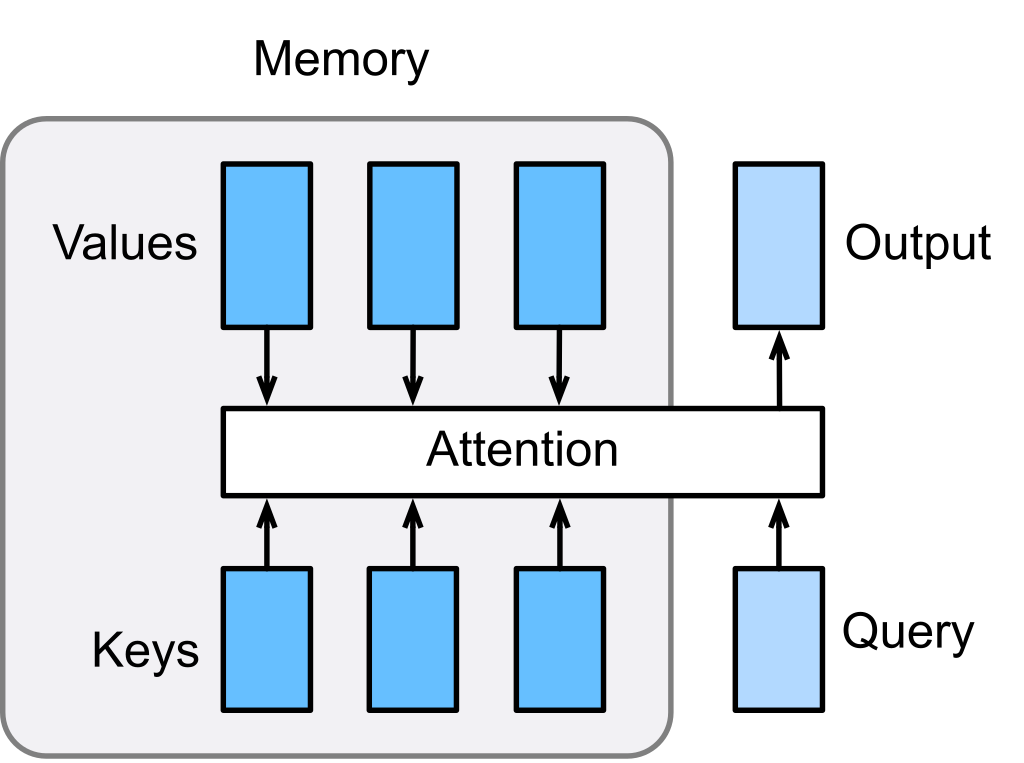

Attention mechanism selects which hidden state from a cell in the encoder to input to a cell in the decoder.
You can see how the model paid attention correctly when outputing “European Economic Area”. In French, the order of these words is reversed (“européenne économique zone”) as compared to English. Every other word in the sentence is in similar order.
“Attention is All You Need” paper

The dominant sequence transduction models are … recurrent or convolutional … encoder-decoder configuration. The best … models also connect the encoder and decoder __ through an __ attention mechanism. We propose a new simple network architecture, the Transformer , based solely on attention mechanisms, …. Experiments on two machine translation tasks show these models to be superior in quality … more parallelizable and requiring significantly less time to train. … We show that the Transformer generalizes well to other tasks …
TL;DR Proposed transformers, using attention mechanism to connect encoder and decoder.
Instead of using a single word vector embedding only, we should also include that particular __ word token in the context of the surrounding words.__
Uses attention layer to mix the context.
Does not need additional recurrence __ or convolutions.__
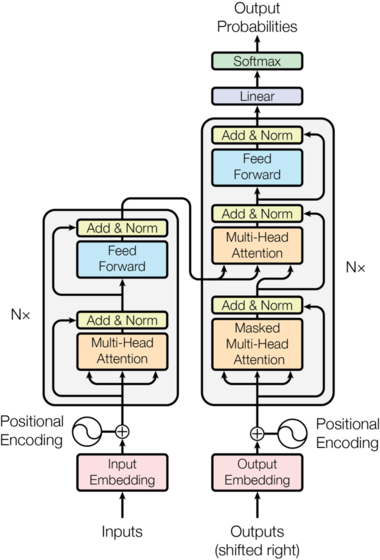
Instead of using a single word vector embedding only, we should also include that particular word token in the context of the surrounding words.
Uses attention layer to mix the context.
Does not need additional recurrence or convolutions.