9. LSTMs and GRUs
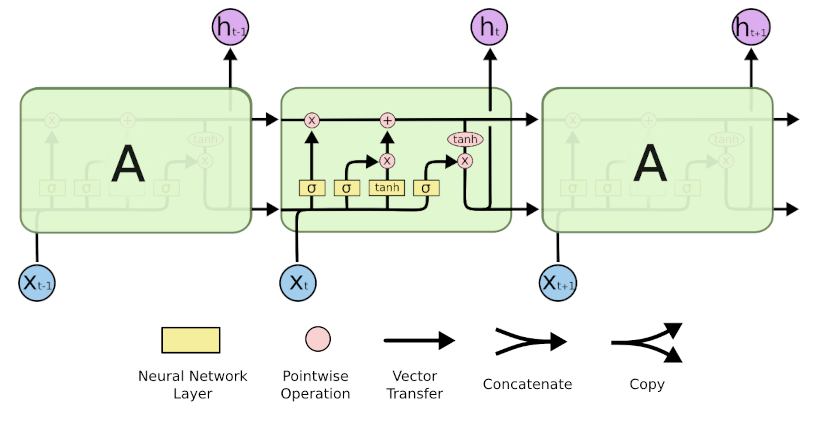
LSTMs structure
A chain-like structure just like RNNs.
4 modules instead of a single hidden layer: the cell state, the forget gate layer, the input gate layer, and the output gate.
Sigmoid and tanh
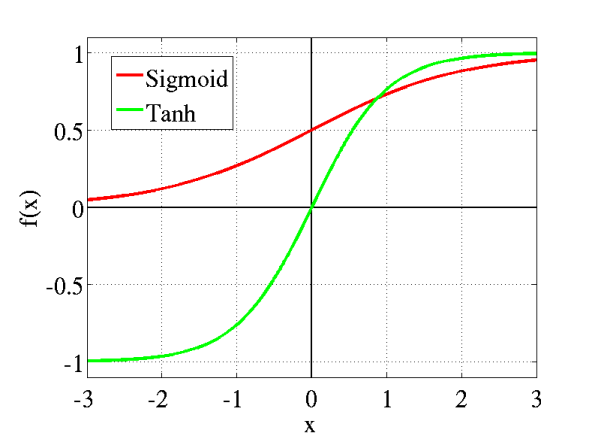
\[\sigma(z)=\frac{1}{1+e^{-z}}\]
\[\text{tanh}(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}}\]
The cell state
The cell state represents the Long-Term Memory
It passes vectors without weights.
LSTM can remove or add information to the cell state
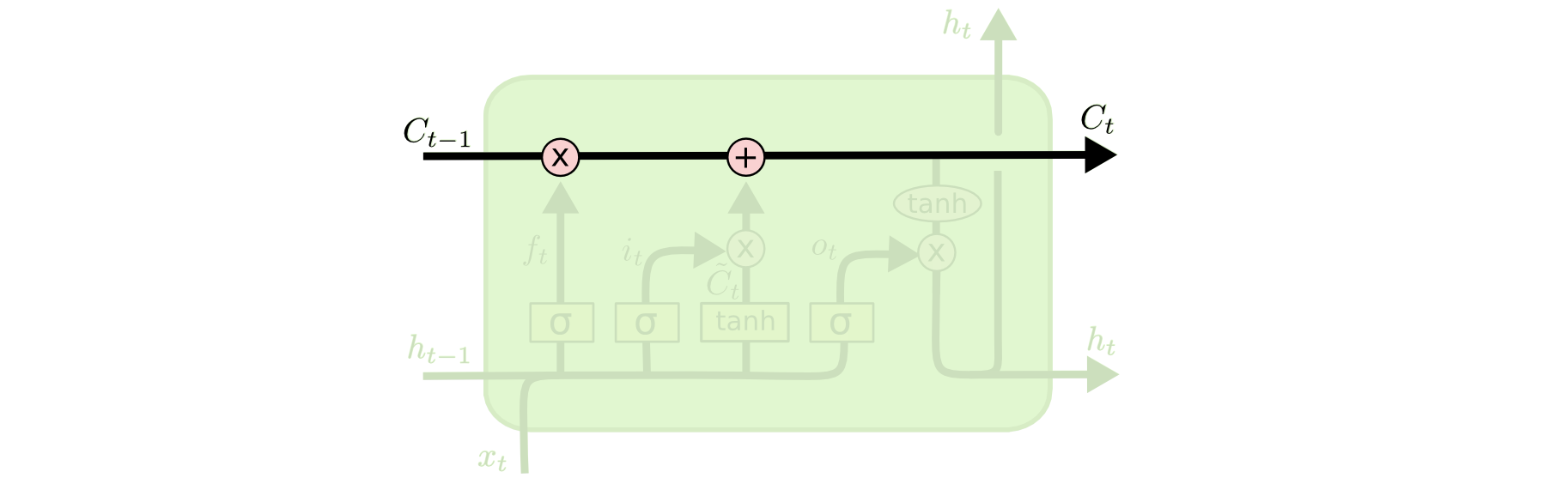
LSTM cell state
The forget gate layer
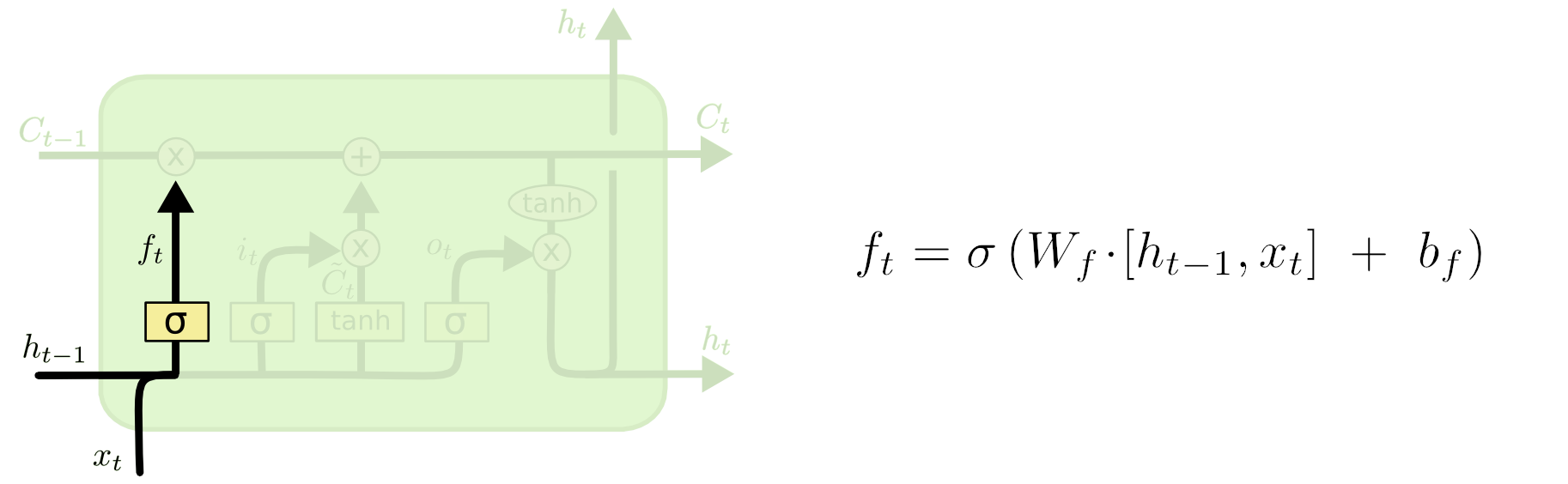
LSTM forget gate
To decide what information we’re keeping from the previous output. It uses a sigmoid function:
- 0 completely forget this
- 1 completely keep this.
Input gate layer
It decides which values we’ll update:
- The
tanhlayer creates a vector of new candidate values, a potential memory to add to the long-term memory - The \(\sigma\) layer decides the percentage of the potential memory to be added to the state.
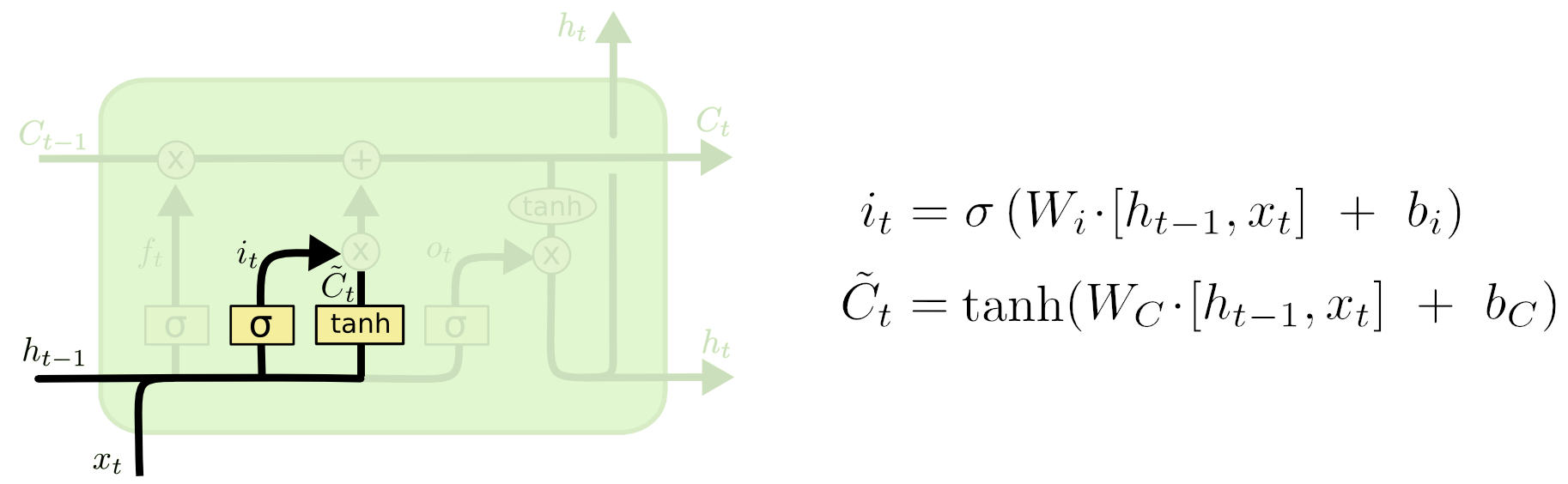
LSTM input gate
Update the cell state
- We forget the things we decided to forget and add the candidate values, scaled by how much we decided to update each state value.
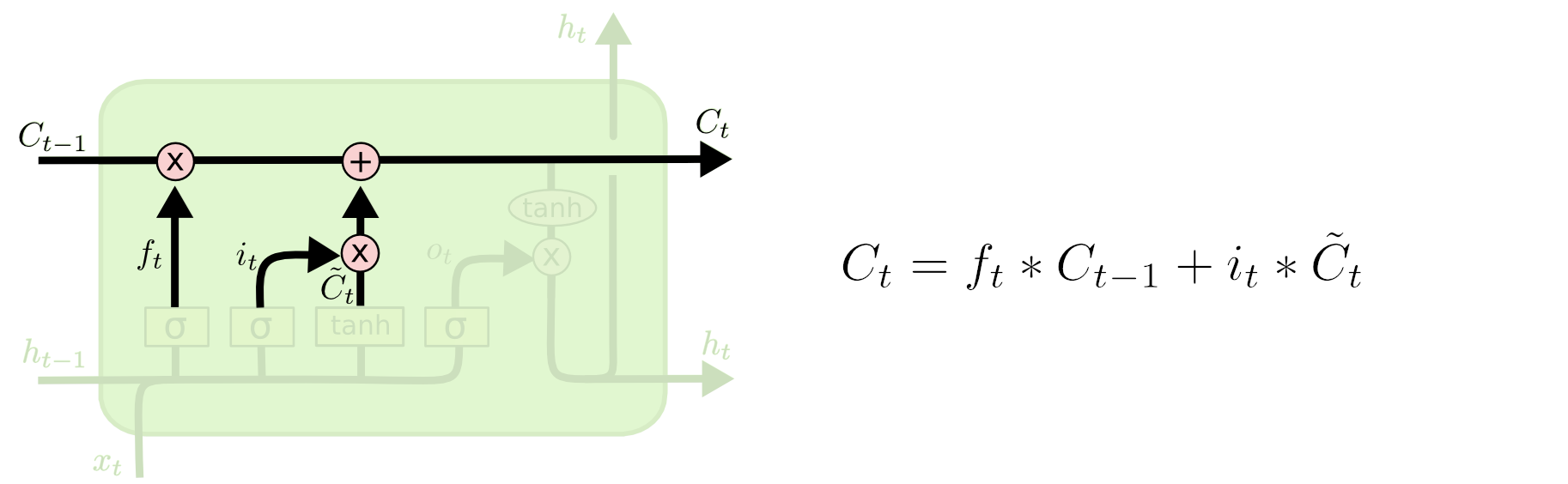
LSTM update cell state
The output gate
It is based on our cell state, but with a filtered version to create a potential new short term memory
Again, a tanh and a \(\sigma\) to decide what to update and by how much.
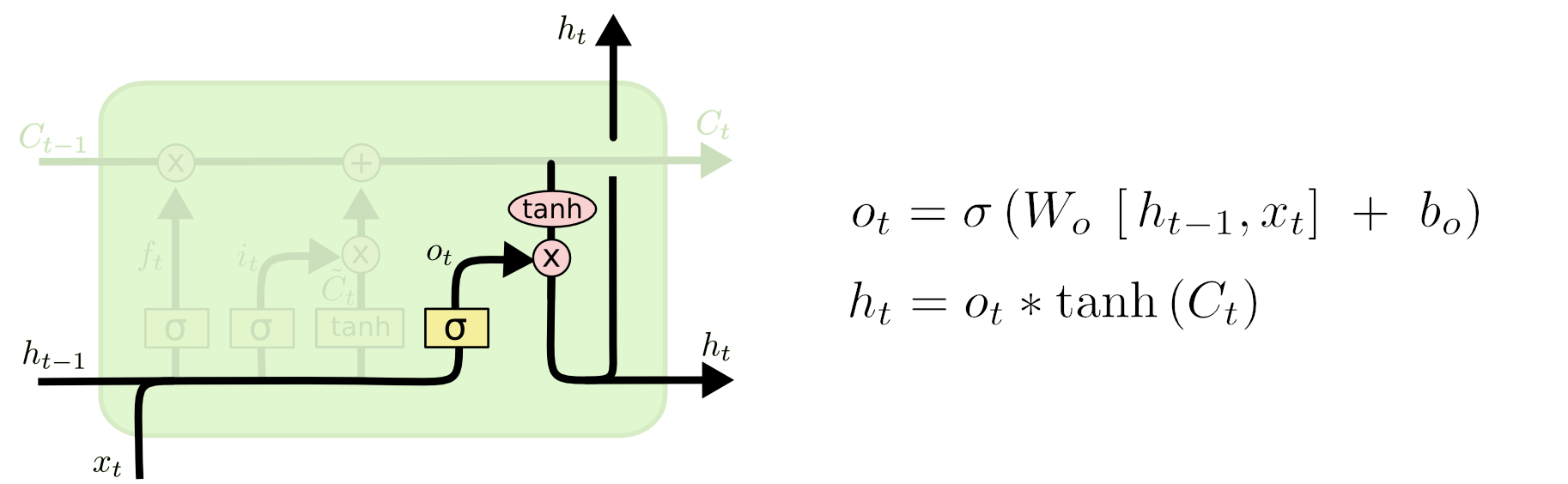
LSTM output gate
Gated Recurrent Unit
A variation of the LSTM with two gates:
- reset gate: how much of the previous state we want to remember
- update gate: how much of the new state we’ll copy to the old one
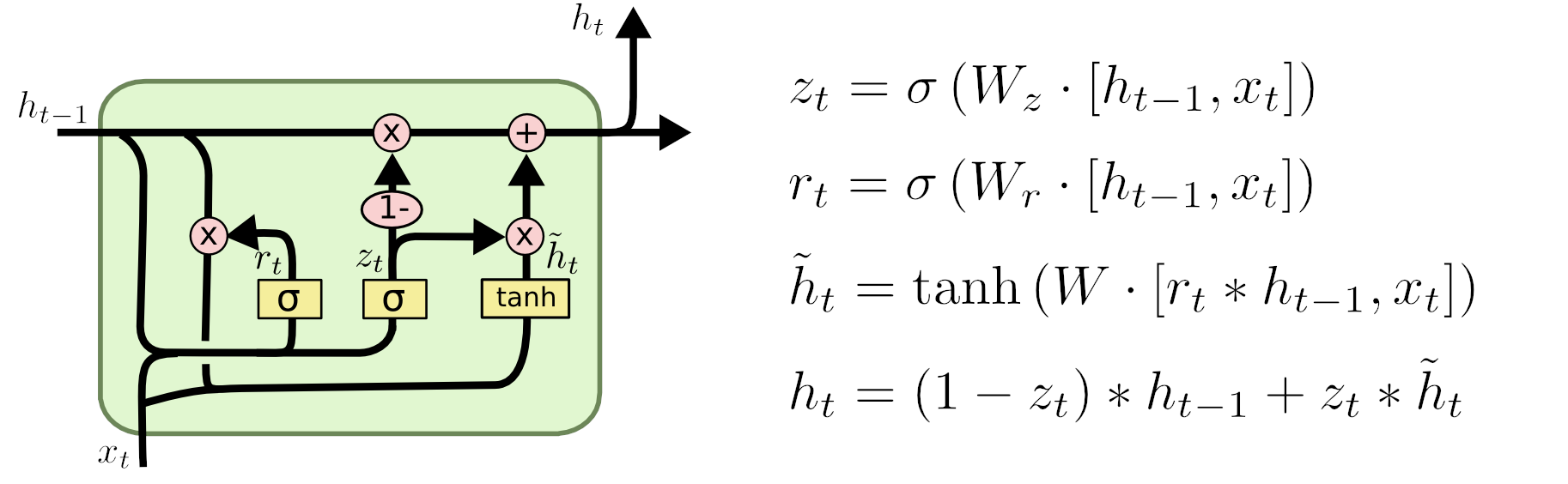
Introduced in 2014, as a simplification of LSTMs, with fewer parameters.
No performance difference between SLTM and GRU