8. Recurrent Neural Networks
Why do we need them?
Vanilla Neural Networks have fixed-sized vector as input and produce a fixed-sized vector as output. They assume inputs and outputs are independent.
Recurrent neural nets allow us to operate over sequences of vectors: sequences in the input, the output, or both.
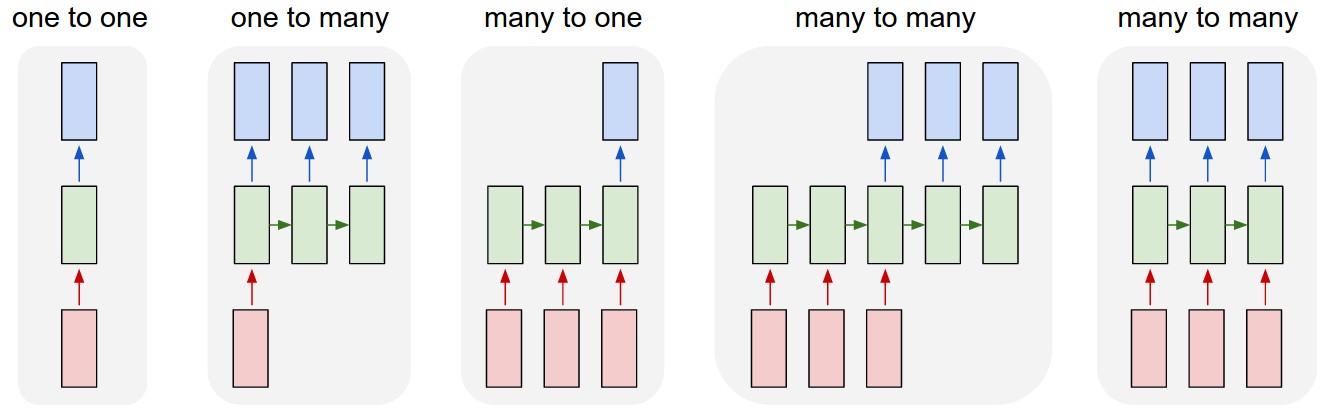
Examples:
(1) Vanilla. (2) Image to sentence of words. (3) Sentence to classification. (4) Sentence translation. (5) Video frames to labeled frames.
They are trained on sequential or time series data where prior elements affect the next output.
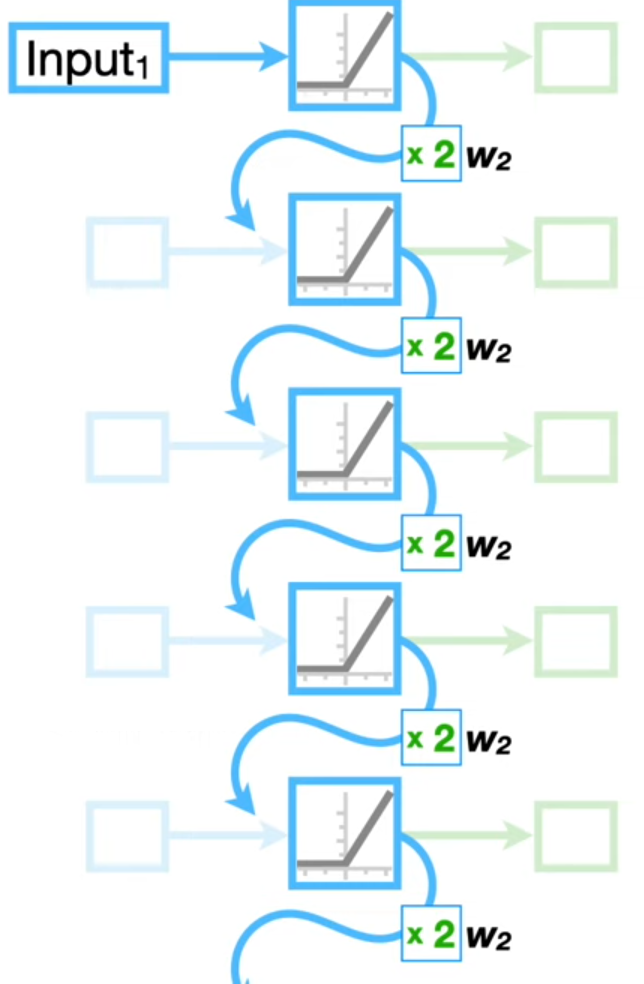
RNNs structure
Recurrent connections: the output of a neuron at one time step is fed back as input to the network at the next time step.
Recurrent unit (v): a single hidden vector updated at each time step.
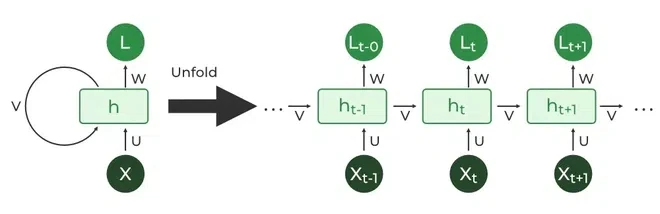
The recurrent unit serves as a form of memory that is based on the current input and the previous hidden state.
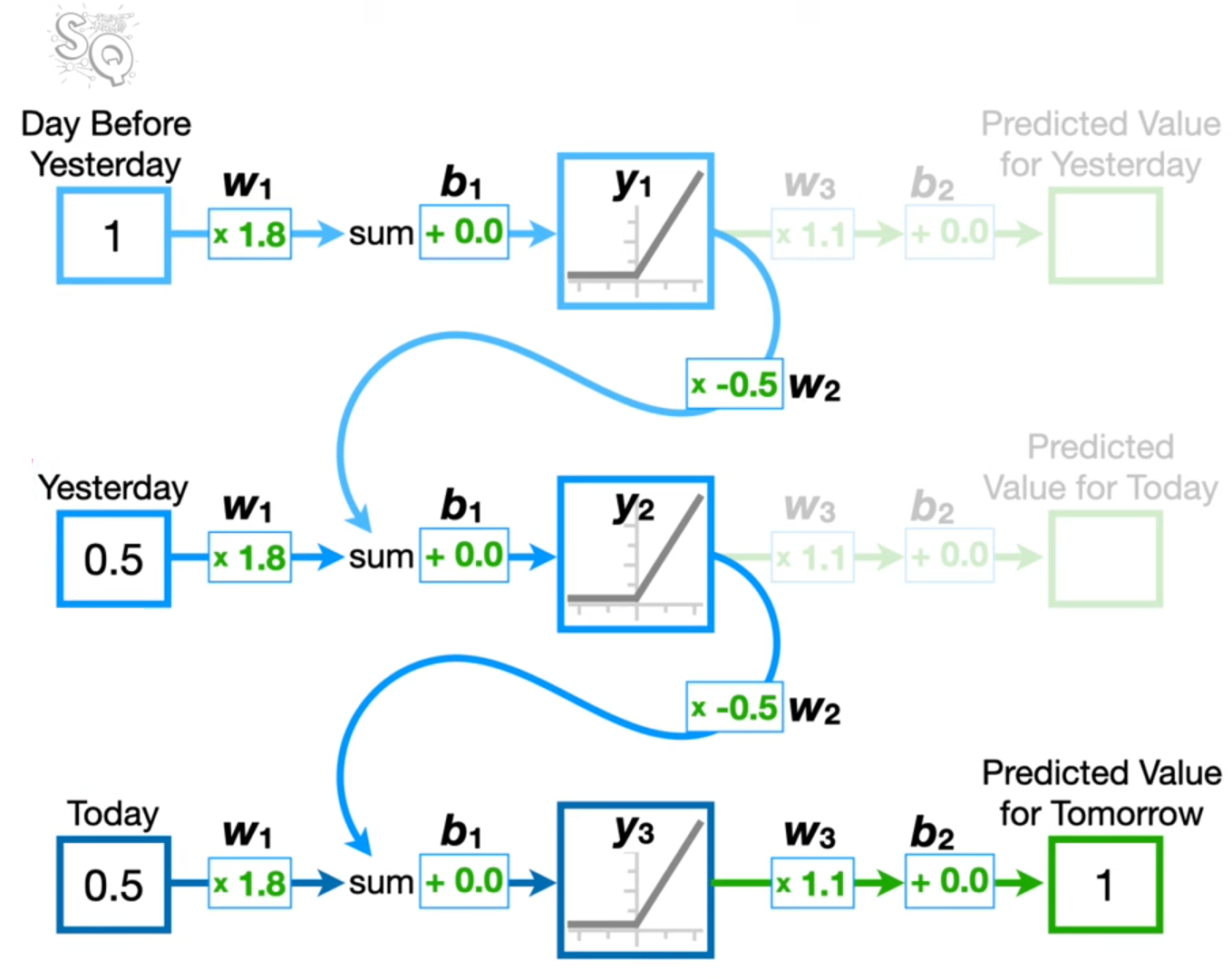
RNN Example from StatQuest
Limitations
Weights in the recurrent vector are uptated with backpropagation.
Partial derivatives cause gradients of earlier weights to be calculated with increasingly many multiplications.
- Vanishing Gradient: If \(w_r < 1\) gradients shrinks over time steps, limiting the ability to learn long-term dependencies.
- Exploding Gradient: If \(w_r > 1\) gradients grow uncontrollably, causing large weight updates that destabilize training.