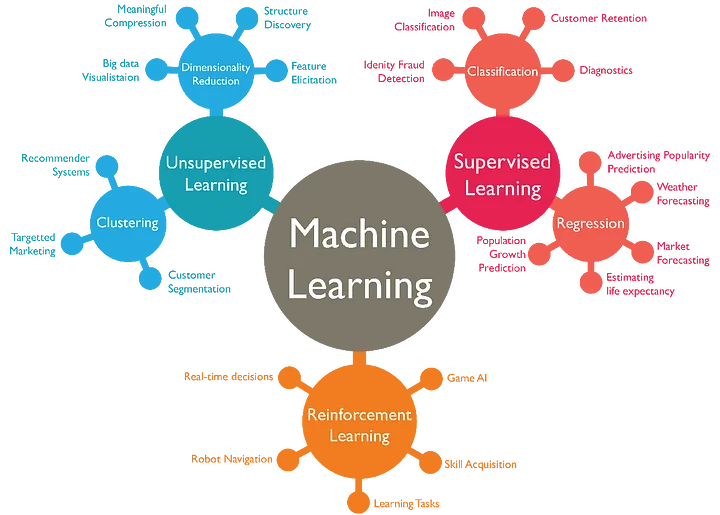
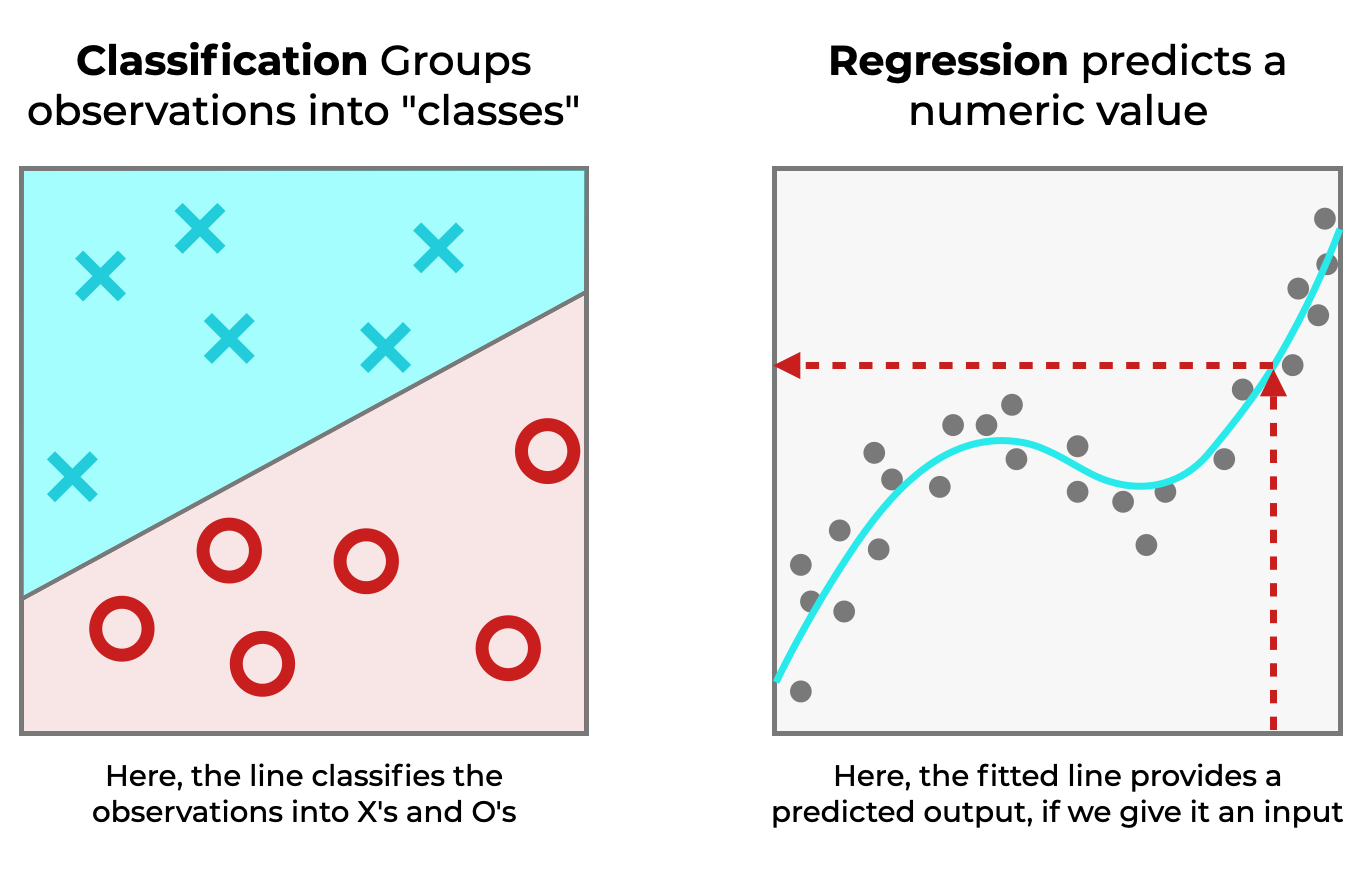
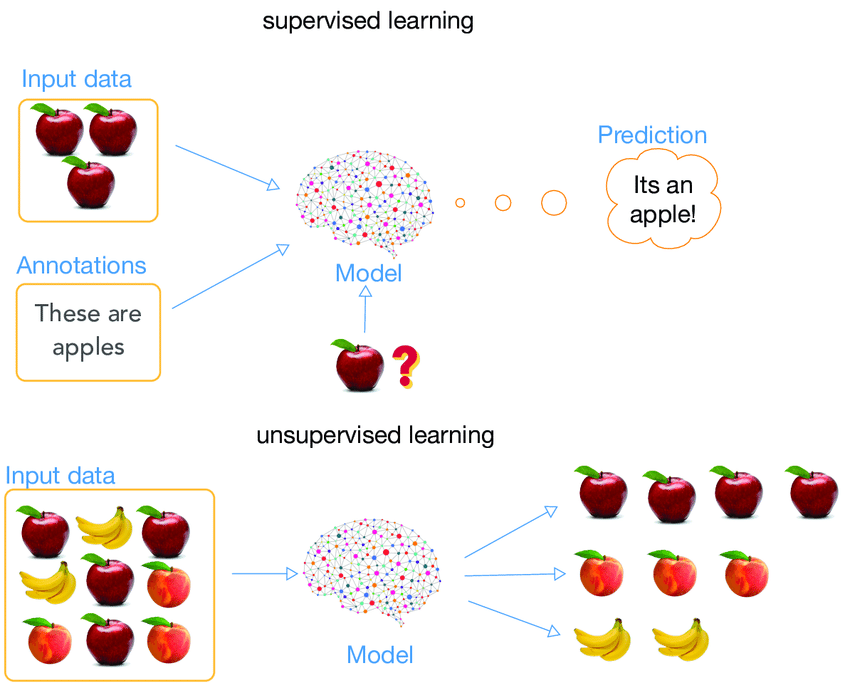
Regression vs Classification
![]()
Regression or Classification
image source: Sharp Sight Labs
Supervised Learning vs Unsupervised Learning
![]()
Supervised or Unsupervised
image source: Ma Yan, et al
Regularization
Loss function \[L(\vec{\beta}) = \text{argmin}_{\vec{\beta}} \sum_{i=1}^{N} \left(y_{i} - \beta_{0} - \sum_{j=1}^{k} \beta_{j}x_{ij}\right)^{2}\]
L1 Regularization \[L(\vec{\beta}, \lambda) = \text{argmin}_{\vec{\beta}} \left[\sum_{i=1}^{N} \left(y_{i} - \beta_{0} - \sum_{j=1}^{k} \beta_{j}x_{ij}\right)^{2} + \lambda\sum_{j=i}^{k}|\beta_{j}|\right]\]
L2 Regularization \[L(\vec{\beta}, \lambda) = \text{argmin}_{\vec{\beta}} \left[\sum_{i=1}^{N} \left(y_{i} - \beta_{0} - \sum_{j=1}^{k} \beta_{j}x_{ij}\right)^{2} + \lambda\sum_{j=i}^{k}\beta_{j}^{2}\right]\]
Empirical Risk Minimization
We can approximate the expected risk over a loss function, data set, and hypothesis model \(h\)
\[\text{E}\left[L((\vec{x}, \vec{y}), h)\right]\] by taking the average over the training data
\[\frac{1}{n}\displaystyle\sum_{i=1}^{n} L((x_{i}, y_{i}), h)\] * formulas outlined by Professor Alexander Jung
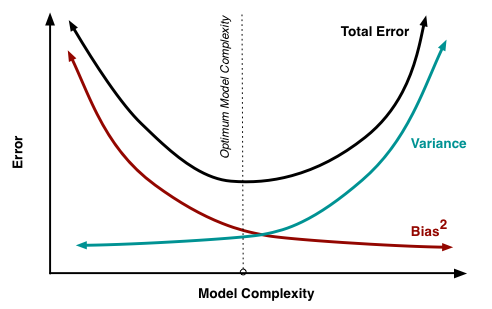
Bias-Variance Tradeoff
Within a hypothesis class of similar modeling functions, we are concerned with the bias-variance tradeoff in model selection.
![]()
bias-variance tradeoff
image source: Scott Fortmann-Roe
Linear Foundations
“For more complex and high-dimensional problems with potential nonlinear dependencies between features, it’s often useful to ask:
- What’s a linear model for the problem?
- Why does the linear model fail?
- What’s the best way to add nonlinearity, given the semantic structure of the problem?